9.2.词法分析
\(9.2.\)Lexical Analysis
1. Tokenizing
In the previous unit, we observed that the syntax analyzer consist of two modules: a tokenizer and a parser:
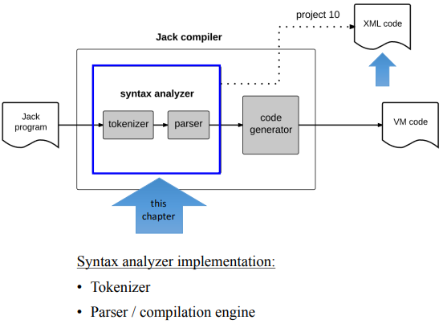
And the tokenizer is an application of a more general area of theory known as lexical analysis. Here's an example of tokenizing in action:
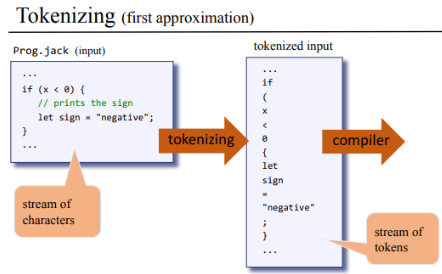
As far as lexical analysis is concerned, the input is nothing more than a stream of characters.
Tokenizing refers to grouping the primitive stream of characters into a stream of meaningful tokens. It provides a very simple yet important preliminary processing of the file.
A token is a string of characters that has a meaning.
- Different programming languages have different definitions of token.
For example,
x++in C makes a lot of sense, but not in Jack, for it doesn't have an++operation.
- Different programming languages have different definitions of token.
For example,
Once we come up with these stream of tokens, we can hand it over to the compiler and completely forget the original input file.
2.Jack tokenizer
In Jack, we have 5 kinds of tokens:

And our tokenizer will provide these useful service:
Handle the compiler's input: It allow us to view the input as a stream of tokens.
Allow advancing the input: It allow us to know:
- If there are more tokens to process.
- What the next token is.
- The value, type of this token.
Supply the value, type of the current token.
Here's an example of a program that use these services:

The TokenizerTest is a program that construct the
tokenizer object. Here's what it does:
- It goes through the input, and for every token, it lists the token to be out of file.
- In the first line,
ifis surrounded by two tags, it describe the type of the token.
And to conduct these functionalities, we can write this pseudo
code: 1
2
3
4
5
6
7
8
9
10tknzr = new JackTokenizer("Prog.jack")
tknzr.advance();
while tknzr.hasMoreTokens() {
tokenclassification= current token classification
print "<" + tokenclassification + ">"
print the current token value
print "</" + tokenclassification + ">"
print newLine
tknzr.advance();
)
We get the first token, and it becomes the current token.
We enter a loop as long as we have more tokens to process.
In each line of the program, we have to output the classification of the token, and we have to do it twice.
We:
- Print the opening tag, then
- Print the value of of the current token,
- Print the token itself,
- At last print end tag with token classification.
We print a newline, and
advance()to get the next token from the tokenizer, until we consume all the tokens from the input file.