9.5.解析器逻辑
\(9.5.\)Parser Logic
1.Parsing logic
In order to carry out parsing, we are going to build a
CompilationEngine class which consist of a set of
methods, one method for every non-terminal rule.
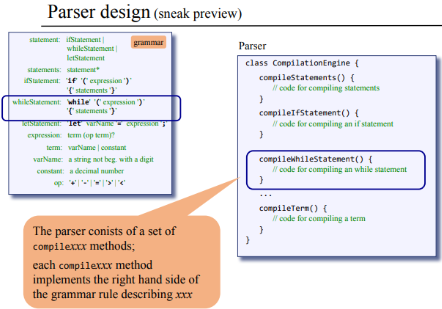
- The code of each
compilexxxmethod follows the right-hand side of the rule xxx - Each
compilexxxmethod is responsible for advancing and handling its own part of the input.
To illustrate this, let's focus on one of these methods
compileWhileStatement:

We follow the right-hand side of the rule, and parse the input it dictates.
- In
whileStatement, it says we should expect to see the tokenwhile. If we find it in the input, we record the fact. Then the left parenthesis, and so on and so forth, - At some point we will get a non-terminal rule like
expression, then we go to next step:
- In
If the right-hand side specifies a non-terminal rule
xxx, we call the corresponding methodcompilexxxWe do this recursively untile we exhaust the input.
And to initialize this process, we:
- Advance the tokenizer.
- Call
compileWhileStatement.
2.Parser design
We also take the compileWhileStatement as an
example:
- If we look at the grammar, we first see that you should see a
while, so we call a methodeat('while'), which means you should expect now to eat thewhiletoken. - We do the same thing
eat('('). - We meet a non-terminal rule
expression, so we callcompileExpression(); - And so on and so forth...
1 | class CompilationEngine { |
When it comes to eat method:
- It's a private method.
- It says you should expect to see the given string, if not, you should throw an error.
- Otherwise, simply advance the input.
1 | eat(string) { |
3.Some observation about grammars and parsing
LL grammar: It's a grammar that can be parsed by a recursive descent algorithm parser without backtracking.
- When you make a decision that what you have is a
whilestatement, you don't have to kind of retract your progress and find out a mistake.
- When you make a decision that what you have is a
LL(k) parser: It's an LL parser that needs to look ahead at most k tokens before you know which rule you are dealing with.
- The grammar we saw so far is LL1, because once we
have a particular token in hand like
let, we immediately know which rule we have to invoke. - There are also things that don't belong to LL1, like English. For example, when we meet a token word "lift", we still have no idea what we should do with it. A verb? A noun? We have to look more tokens downstream to know which rule to use. In this process, we may need to backtrack and reconsider some of the rules we have to use...
- The grammar we saw so far is LL1, because once we
have a particular token in hand like