15.2.Trie的实现
\(15.2\)\(Trie\)的实现
1.\(Trie\)的介绍
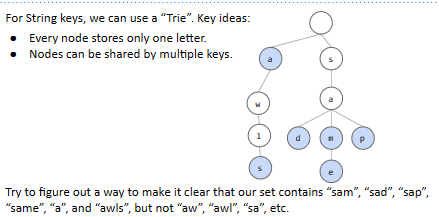
在\(Trie\)中,我们使用以下的计策来存储一系列单词(字符串):
- 每个节点只存储一个字母。
- 每个节点可以被多个键共用。
下面的树结构即是一组单词的\(Trie\),蓝色意味着这是一个单词的结尾:
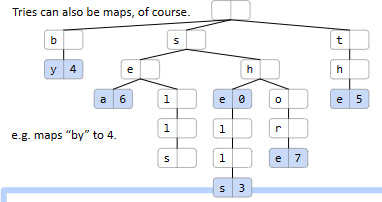
同样地,\(Trie\)亦可用作\(map\):
需要注意,当我们需要处理某个特定(\(specificity\))的问题时,我们可以改进我们原有的、通用的数据结构(通常是对其加以限制(\(constraint\))),来更好地实现我们想要的功能。例如,如果我们用\(HashMap\)来实现对单词的存放,那么我们的查找就需要遍历所有已有的字符串,这样的效率显然很低。
\(ADT\)与特殊实现(\(specific\;implementations\))是有区别的。例如,并查集是一种\(ADT\),它具有
connect(x, y)与isConnected(x, y)两个方法。而这来个方法有四种不同的实现方式:\(Quick\;find\)、\(Quick\;union\)、\(Weight\;QU\)、\(WQUPC\)。在这里,\(Trie\)就是当\(Set\)或\(Map\)存储的数据类型是字符串时的特殊实现:
- We give each node a single character and each node can be a part of several keys inside of the trie.
- Searching will only fail if we hit an unmarked node or we fall off the tree
- Short for Retrieval tree, almost everyone pronounces it as "try" but Edward Fredkin suggested it be pronounced as "tree"
2.\(Trie\)的构建
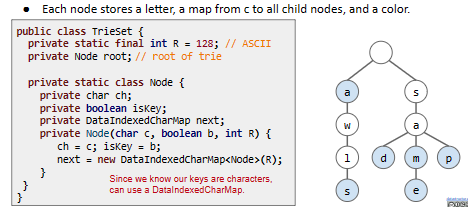
利用先前的策略,我们让每个节点存储字母、孩子和颜色。由于每个节点都是一个字母,我们可以用DataIndexedCharMap来存储节点的所有孩子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29public class DataIndexedCharMap<V> {
private V[] items;
public DataIndexedCharMap(int R) {
items = (V[]) new Object[R];
}
public void put(char c, V val) {
items[c] = val;
}
public V get(char c) {
return items[c];
}
}
public class TrieSet {
private static final int R = 128; // ASCII
private Node root; // root of trie
private static class Node {
private char ch;
private boolean isKey;
private DataIndexedCharMap next;
private Node(char c, boolean blue, int R) {
ch = c;
isKey = blue;
next = new DataIndexedCharMap<Node>(R);
}
}
}
然而,当我们的节点只有很少的孩子时,由于我们创建了\(128\)个空间,只有很少的空间是真正被使用的。
注意到两个节点间存在链接当且仅当两个节点都存储了字符,我们可以删掉\(Node\)的\(ch\)变量,而用该节点在父节点的\(next\)中的位置来表征: 1
2
3
4
5
6
7
8
9
10
11
12
13
14public class TrieSet {
private static final int R = 128; // ASCII
private Node root; // root of trie
private static class Node {
private boolean isKey;
private DataIndexedCharMap next;
private Node(boolean blue, int R) {
isKey = blue;
next = new DataIndexedCharMap<Node>(R);
}
}
}
同时,为了减少空间浪费,我们可以用\(HashMap\)代替\(DataIndexedCharMap\): 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17import java.util.HashMap;
import java.util.Map;
public class TrieSet {
private Node root; // root of trie
private static class Node {
private boolean isKey;
private Map<Character, Node> next;
private Node(boolean isKey) {
this.isKey = isKey;
this.next = new HashMap<>();
}
}
}
3.\(Trie\)的运行时间
给定字符串的\(Trie\),其对应的\(Map\)、\(Set\)操作运行时间如下:
add:\(\Theta(1)\)contains:\(\Theta(1)\)
这是因为\(Trie\)的运行时间只取决于单词的长度,而与\(Trie\)中键的多少无关。我们在查询时只会遍历我们需要的单词。