16.2.K-D树
\(16.2\)\(K-D\;Trees\)
1.引入
对于二维的空间,我们可以利用四叉树完成搜索。那对于更高维的空间呢?比如下面的例子:
Example: Want to find songs with the following features:
- Length between 3 minutes and 6 minutes.
- Between 1000 and 20,000 listens.
- Between 120 to 150 BPM.
- Were recorded after 2004.
这时,我们就可以采用\(K-D\;Tree\)的数据结构来对数据进行划分,从而优化搜索。
2.\(K-D\)树的原理与构造
以二维坐标为例,我们按照以下的规则构建\(K-D\;Tree\):
Each level has a "cutting dimension"
Cycle through the dimensions as you walk down the tree.
Each node contains a point P = (x,y)
To find (x',y') you only compare coordinate from the cutting dimension
- e.g. if cutting dimension is x, then you ask: is x’ < x
每个节点都拥有两个子空间。在搜索中,我们像在四叉树中做的一样,只在可能有最优解的子空间进行搜索。
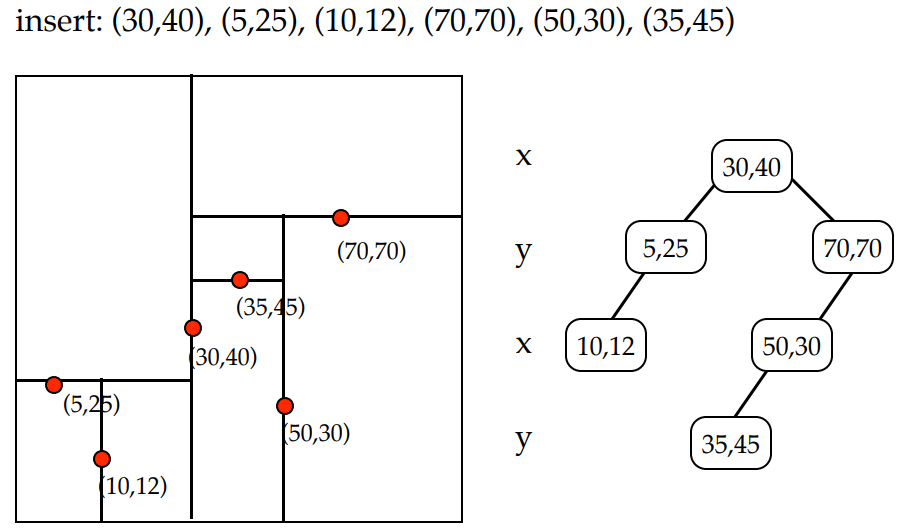
例如,我们可以如下插入以下坐标:
3.\(K-D\)树的搜索
以搜索到某个点距离最小的点为例,我们可以按照以下的步骤进行搜索:
Start at the root and store that point as the "best so far". Compute its distance to the query point, and save that as the "score to beat". In the image above, we start at A whose distance to the flagged point is 4.5.
This node partitions the space around it into two subspaces. For each subspace, ask: "Can a better point be possibly found inside of this space?" This question can be answered by computing the shortest distance between the query point and the edge of our subspace (see dotted purple line below).
Continue recursively for each subspace identified as containing a possibly better point.
In the end, our "best so far" is the best point; the point closest to the query point.