4.1.Caches
\(4.1.\)Caches
1. Some concepts & Library analogy
Suppose you were a student writing a term paper on important historical developments in computer hardware. You are sitting at a desk in a library with a collection of books that you have pulled from the shelves and are examining. You find that several of the important computers that you need to write about are described in the books you have, but there is nothing about the EDSAC. Therefore, you go back to the shelves and look for an additional book. You find a book on early British computers that covers the EDSAC. Once you have a good selection of books on the desk in front of you, there is a high probability that many of the topics you need can be found in them, and you may spend most of your time just using the books on the desk without returning to the shelves. Having several books on the desk in front of you saves time compared to having only one book there and constantly having to go back to the shelves to return it and take out another.
The same principle allows us to create the illusion of a large memory that we can access as fast as a very small memory. Just as you did not need to access all the books in the library at once with equal probability, a program does not access all of its code or data at once with equal probability. Otherwise,it would be impossible to make most memory accesses fast and still have large memory in computers, just as it would be impossible for you to fit all the library books on your desk and still find what you wanted quickly.
The above line illustrates the principel of locality. There are two kinds of localities:
Temporal locality(locality in time): If an item is referenced, it will tend to be referenced again soon. (If you recently brought a book to your desk to look at, you will probably need to look at it again soon.)
Spatial locality (locality in space): If an item is referenced, items whose addresses are close by will tend to be referenced soon. (For example, when you brought out the book on early English computers to learn about the EDSAC, you also noticed that there was another book shelved next to it about early mechanical computers, so you likewise brought back that book and, later on, found something useful in that book.)
We take advantage of the principle of locality by implementing the memory as a memory hierarchy. It contains multiple levels, but data are copied between only two adjacent levels at a time.
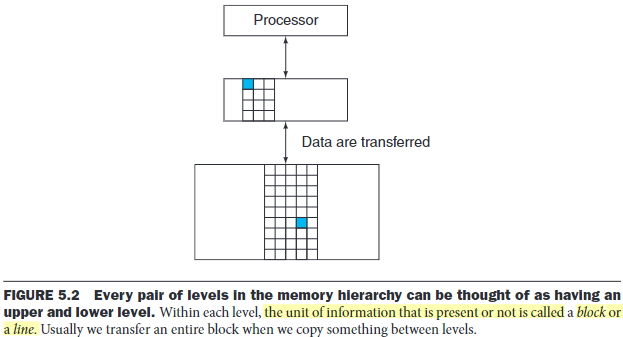
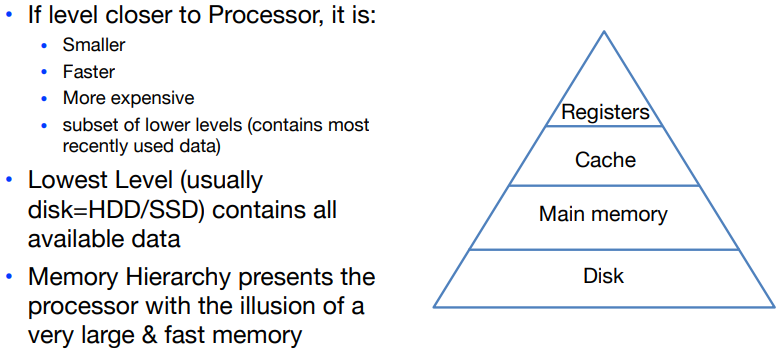
The faster memories are more expensive per bit than the slower and thus are smaller.

- If the data requested by the processor appear in some block in the upper level, it's called a hit(like you find a book on your desk). Else it's called a miss.
2.Memory technologies

3.Caches basics
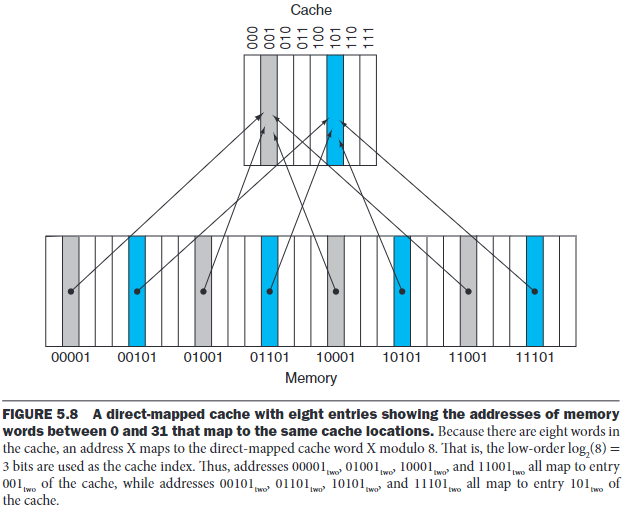
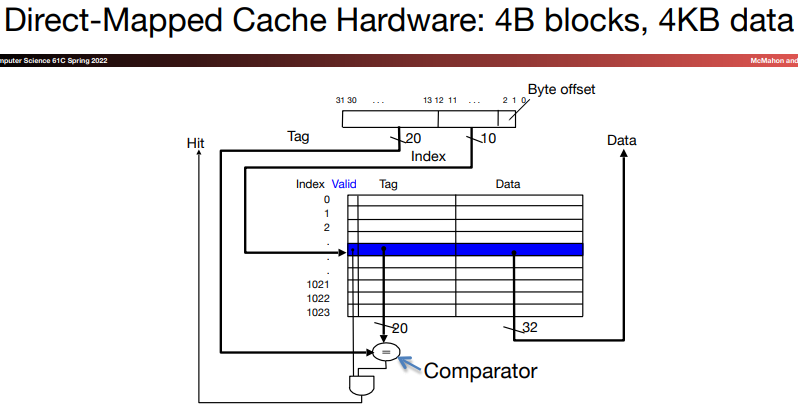
\(a.\)Direct-mapped structure
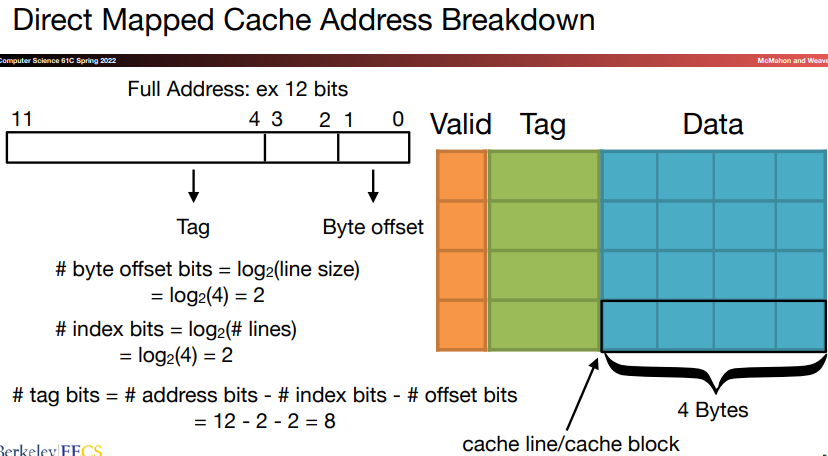
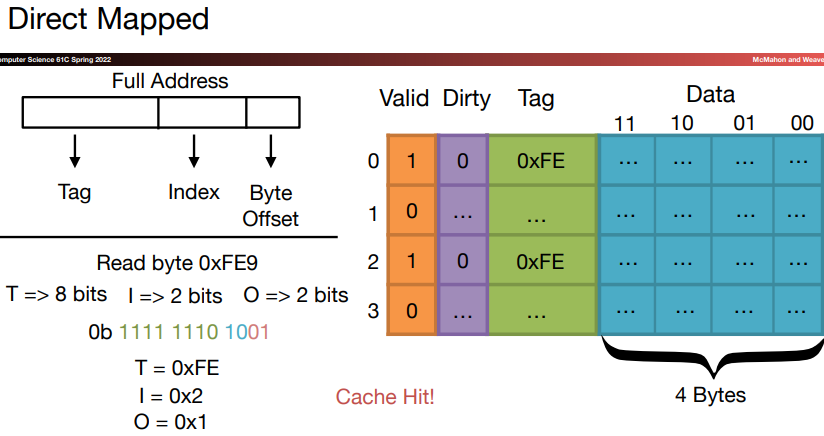
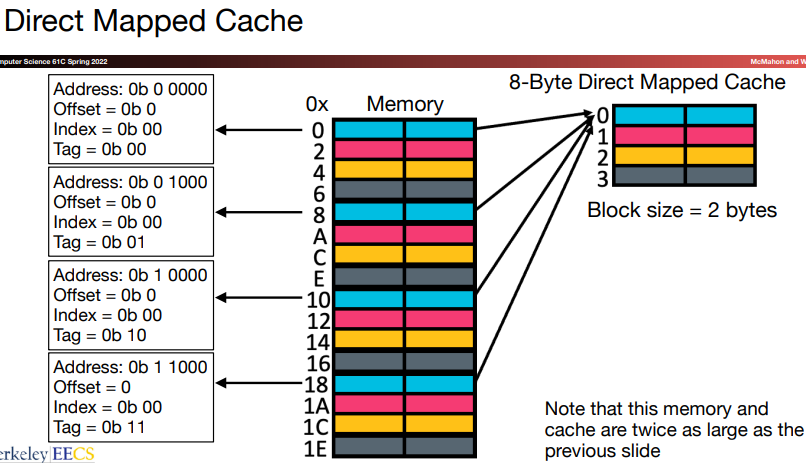
For each word, we can assign a location in cache based on the address of the word in memory, and this is called direct-mapped.
The struction uses this mapping to find a block:
\[ (blockAddress)\mod (numberOfBlockInCache) \]
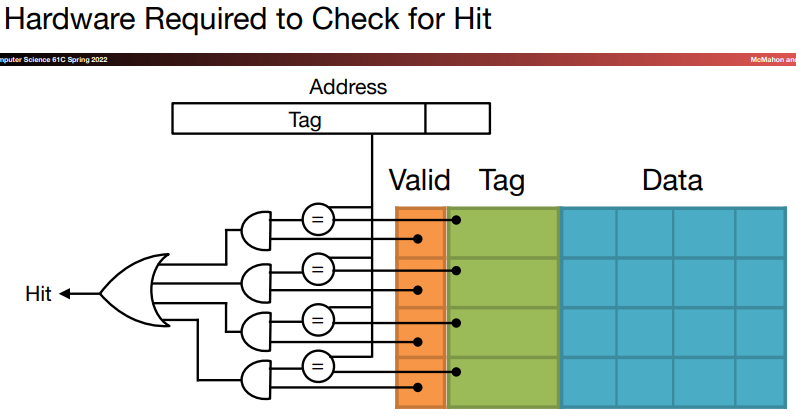
- We add a set of tags to the cache to judge if the data in the cache corresponds to a requested word. The tag needs to contain the upper portion of the address:
We add a valid bit to indicate whether an entry contains a valid address. If the bit isn's set, there cannot be a match for this block.
A cache index is used to select the block.
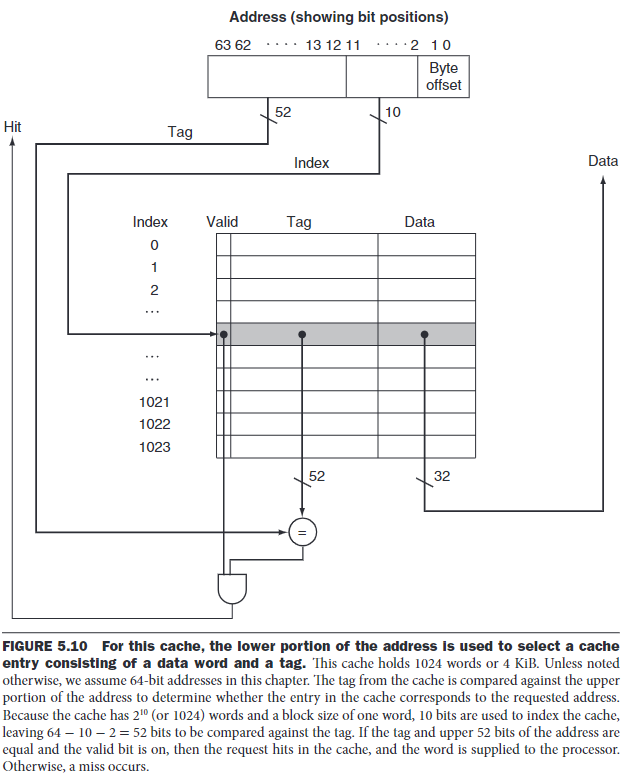
The digit capacity of tage field and the total number of bits in the struction can be calculated by the following steps:

\(b.\)Dealing with missing rate
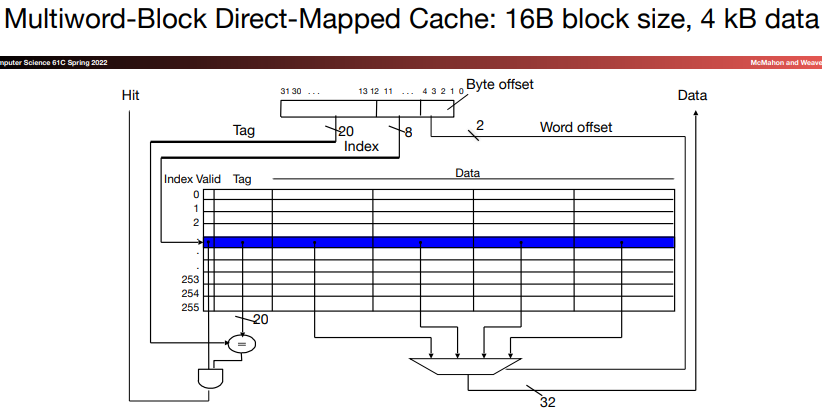
Larger blocks exploit spatial locality to lower miss rates. This is because larger blocks contain more adjacent data, taking advantage of locality of reference, making it more likely that programs will hit the cache when they access the data.
However, the miss rate may go up eventually if the block size becomes a significant fraction of the cache size, for there will be a great deal of competition for those blocks. As a result, a block will be bumped out of the cache before its words are accessed.
Also, enlarging the block size makes the miss penalty larger.
The miss penalty is determined by the time required to fetch the block from the next lower level of the hierarchy and load it into the cache.
The time to fetch the block has two parts: the latency to the first word and the transfer time for the rest of the block.
4.Handling cache misses
The cache miss handling is done in collaboration with the process control unit and with a separate controller that initiates the memory access and refills the cache.
- The control unit in cache must detect a miss and process the miss by fetching the requested data from memory. If the cache reports a hit, it uses the data as usual.
To handle the instruction misses, we need to:
Send the original PC value to the memory. It equals to
PC-4.Instruct main memory to perform a read and wait for the memory to complete its access.
Write the cache entry, putting the data from memory in the data portion of the entry, writing the upper bits of the address(from the ALU)into the tag field, and turning the valid bit on.
Restart the instruction execution at the first step, which will refetch the instruction, this time finding it in the cache.
5.Handling writes
\(a.\)Write-through
One simple way to deal with write hit is always to write the data into both the memory and the cache. However, the write to main memory takes a long time, thus reduce the performance.
One solution is to use a write buffer. It stores the data while they are waiting to be written to memory.
After writing the data into the cache and the write buffer, the processor continues execution.
When a write to main memory completes, the entry in the write buffer is freed.
If the write buffer is full when the processor reaches a write, the processor must stall until there's an empty position in the buffer.
\(b.\)Write-back
When a write occurs, the new value is written only to the block in the cache. The modified block is written to the lower level of the hierarchy when it's replaced. This scheme is called write-back. It can improve performance especially if processors can generate writes faster than writes can be handled by the main memory.
In the write-through process, we can simply overwrite the block. But in a write-back process, if we overwrite a block before we knew whether the store had hit the cache, we may destroy the contents of the block which isn't backed up. To avoid this, we take the two methods:
We use two cycles, one to check for hit and one to perform the write.
Or we can use a store buffer to hold the data. When it's used, the processor does the cache lookup and places the data in the store buffer during the normal cache access cycle. The new data are written from the store buffer into the cache on the next unused cache access cycle.
By comparison, we can always use one cycle to do writing in write-through process. We read the tag and write the data portion of the selected block. If the tag matches the address of the current block, the processor continues normally, since the correct block has been updated. Otherwise, the processor generates a write miss to fetch the rest of the block corresponding to that address.
Many write-back caches also include write buffers that are used to reduce the miss penalty when a miss replaces a modified block. In such a case, the modified block is moved to a write-back buffer associated with the cache while the requested block is read from memory. The write-back buffer is later written back to memory.
The main idea is not to touch the main memory as much as possible.


\(c.\)Write-allocate & No write-allocate
In write-through process, to deal with the write miss, we allocate a block in the cache called write allocate. The block is fetched from memory and then the appropriate portion of the block is overwritten.
This reduces the number of accesses to main memory and increases the speed of access.
Another strategy is to update the portion of the block in memory but not put it in the cache. This is because sometimes we need to write in the entire blocks of data, and in such situation writing in cache is unnecessary.


Since write-through strategy ensures the consistence between memory and cache, if we use write-allocate strategy, the cache will contain reduntant data block, which makes cache management more difficult.
And for write-back, this ensures the data consistence.
\(d.\)An example
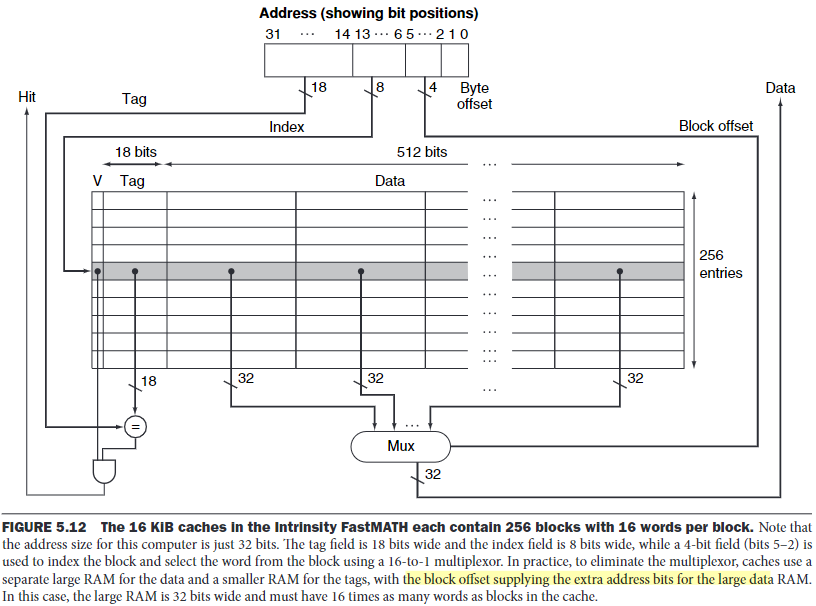
In this design, the steps for reading request are as follows:
Send the address to the appropriate cache.
If the cache signal hit, the requested word is available on the data lines. A block index field is used to control the multiplexor to select the required word from the 16 words in the indexed block.
If the cache signals miss, we send the address to the main memory. When the memory returns with the data, we write it into the cache and then read it to fulfill the request.
6.Cache performance improvement
There are two different techniques to improve cache performance. One focuses on reducing the miss rate by reducing the probability that two distinct memory blocks will contend for the same cache location. The other reduces the miss penalty by adding an additional level to the hierarchy. The second technique is called multilevel caching.
\(a.\)More flexible placement of blocks
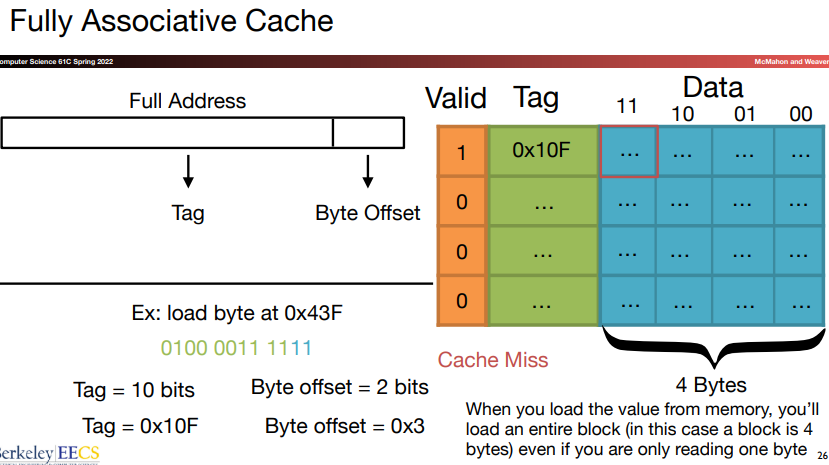
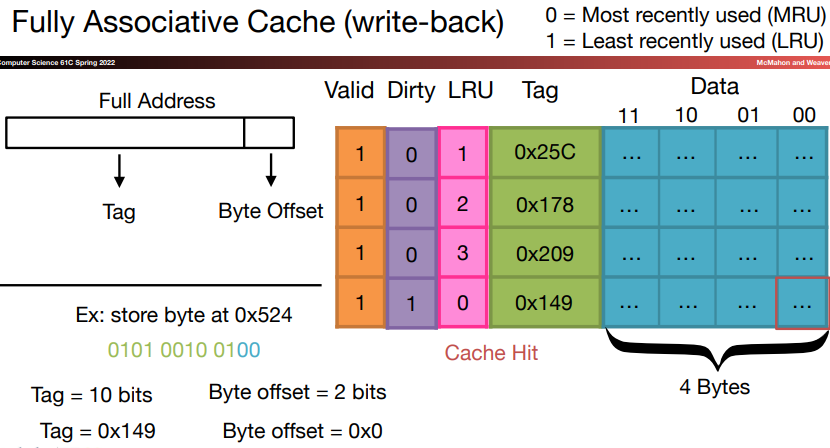
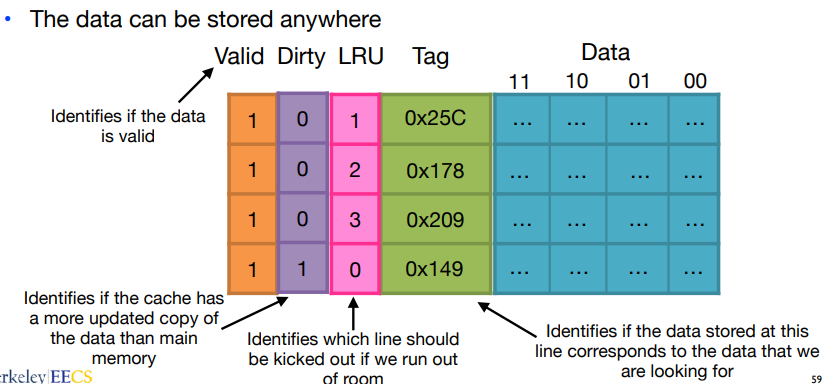
Fully associative: In this scheme, a block can be placed in any location in the cache, that is, the block may be associated with any entry in the cache.
To find a given block in a fully-associative cache, all the entries in the cache must be searched.
This process is done in parallel with a comparator associated with each cache entry. This comparators significantly increase the hardware cost, so the scheme only suits for caches with small numbers of blocks.
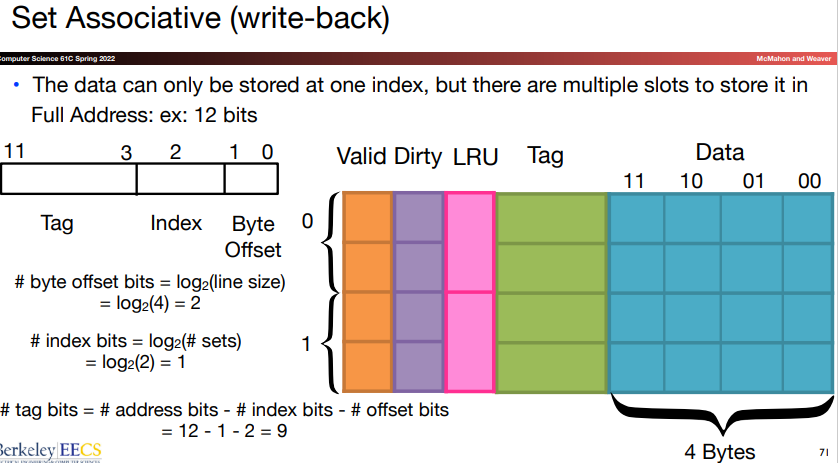
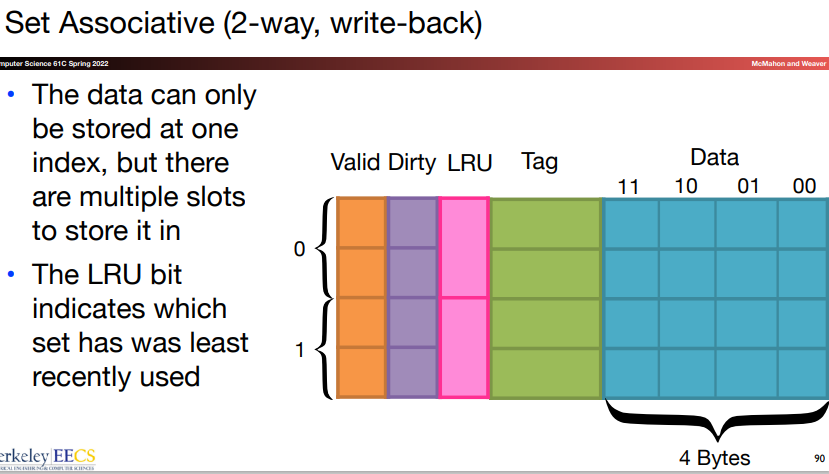
Set associative: In this scheme, there are a fixed number of locations where each block can be placed. An n-way set associative cache consists of a number of sets, each of which has \(n\) blocks.
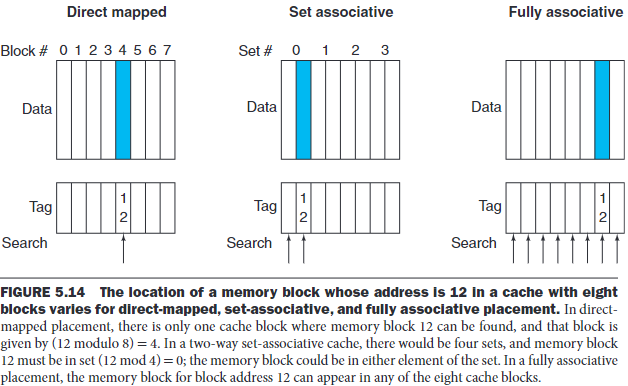
The advantage of increasing the degree of associativity is that it usually decrease the miss rate. However, there's little further improvement in going to rather higher associativity.
\(b.\)Locating a block in the cache
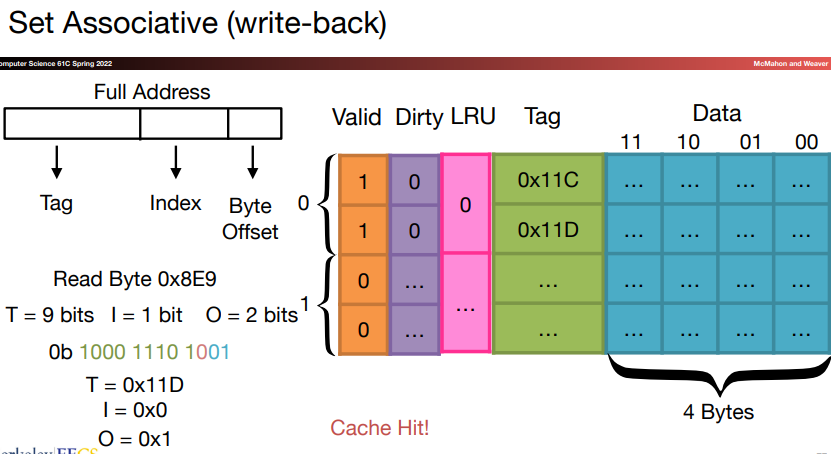
Let's first take a block in a set-associative cache for example:

The tag is checked to see if it matches the block address from the processor.
The index is used to select the set containing the address of interest.
All the tags in the selected set are searched in parallel.
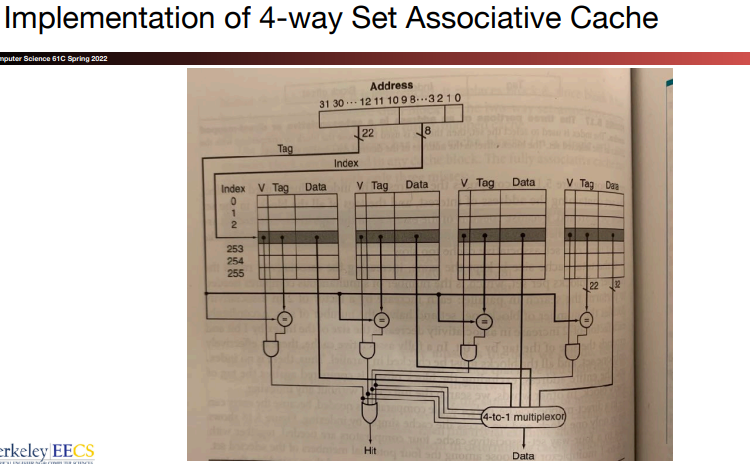
In a direct-mapped cache, only a single comparator is needed, and we access the cache simply by indexing. In a four-way set-associative cache, four comparators are needed, together with a 4-to-1 multiplexor to choose among the four potential sets. The cache access consists of indexing the appropriate set and then searching the tags of the set.
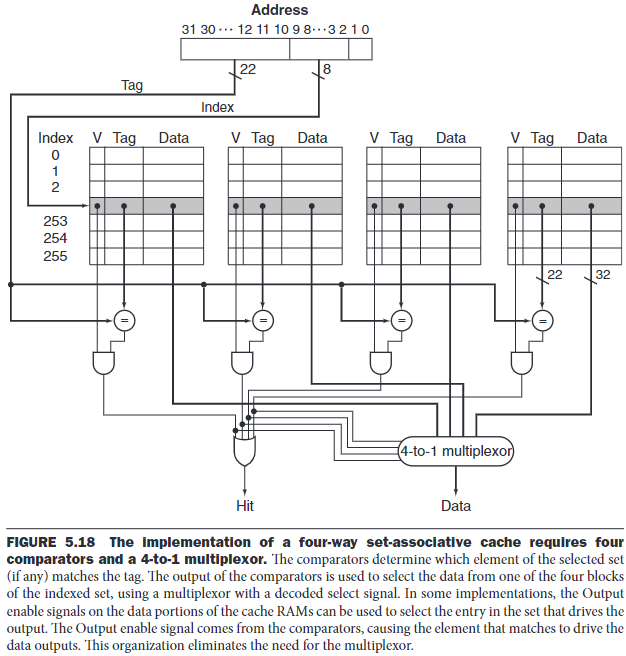
The choice among these three scheme depends on the cost of a miss versus the cost of implementing associativity.
\(c.\)Choosing which block to replace
There are two primary strategies for replacement in set-associative or fully associative caches:
Random: Candidate blocks are randomly selected, possibly using some hardware assistance.
Least recently used(LRU): The block replaced is the one that has been unused for the longest time.
In practice, LRU is too costly to implement for hierarchies with more than a small degree of associativity, since tracking the usage information is expensive.
\(i.\)Approximate LRU


\(d.\)Multilevel caches
To close the gap between the fast clock rates of processors and the long time to access DRAMs, most microprocessors support an addition level of caching.
The second-level cache is normally on the chip, and is access whenever a miss occurs in the primary cache.
If the second-level cache contains the desired data, the miss penalty for the first-level cache will be the access time of the second-level cache, which is much less time.
The design considerations for a primary and secondary cache are different. This two-level structure allows the primary cache to focus on minimizing hit time to yield a shorter clock cycle or fewer pipeline stages, while allowing the second cache to focus on miss rate to reduce the penalty of long memory access times.
The primary cache is smaller, and may use a smaller block size to go with the smaller cache size and reduce miss penalty.
The second cache will be much larger than in a single-level cache. It also use higher associativity than the primary cache, both for reducing the miss rates.

7.Three Cs
In the hierarchy model, all misses are classified into one of three categories:
Compulsory misses: These are cache misses caused by the first access to a block that has never been in the cache. These are also called cold-start misses.
Capacity misses: These are cache misses caused when the cache cannot contain all the blocks needed during execution of a program. Capacity misses occur when blocks are replaced and then later retrieved.
Conflict misses: These are cache misses that occur in set-associative or direct-mapped caches when multiple blocks compete for the same set. These cache misses are also called collision misses.
Increasing associativity reduces conflict misses, but associativity may slow access time, leading to lower overall performance.
Capacity misses can be reduced by enlarging the cache(so second-level caches is large). Meanwhile, when we make the cache larger, we must also be careful about increasing the access time(so the first-level caches is small).
Since compulsory misses are generated by the first reference to a block, we can simple increase the block size to reduce the block number.
8.Using FSM to control a cache
\(a.\)Finite-State Machines
A FSM consists of a set of states and directions on how to change states.
The directions are defined by a next-state function, which maps the current state and the inputs to a new state.
Each state of FSM specifies a set of outputs that are asserted when the machine is in this state.
A FSM can be implemented with a temporary register that holds the current state and a block of combinatinoal logic that determines both the data-path signals to be asserted and the next state.
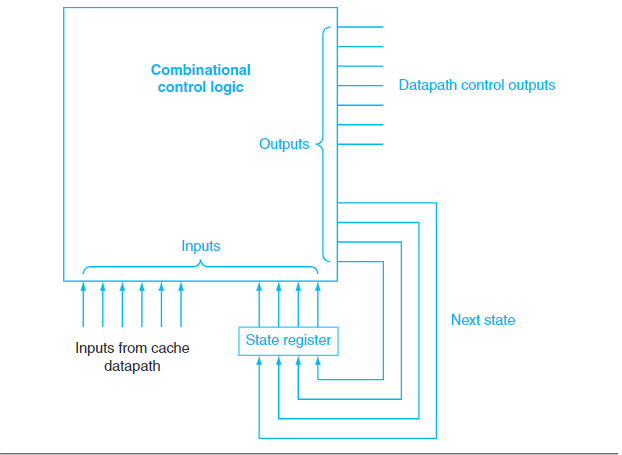
\(b.\)Controller
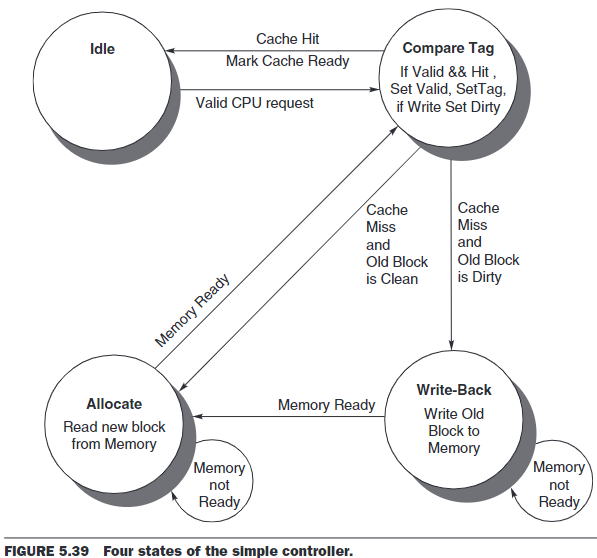
Ideal: This state waits for a valid read or write request from the processor, which moves the FSM to the Compare Tag state.
Compare Tag: This state tests to see if the requested read or write is a hit or a miss. The index portion of the address selects the tag to be compared. If the data in the cache block referred to by the index portion of the address are valid, and the tag portion of the address matches the tag, then it is a hit. Either the data are read from the selected word if it is a load or written to the selected word if it is a store. The Cache Ready signal is then set. If it is a write,the dirty bit is set to 1. Note that a write hit also sets the valid bit and the tag field; while it seems unnecessary, it is included because the tag is a single memory, so to change the dirty bit we likewise need to change the valid and tag fields. If it is a hit and the block is valid, the FSM returns to the idle state. A miss first updates the cache tag and then goes either to the Write-Back state, if the block at this location has dirty bit value of 1, or to the Allocate state if it is 0.
Write-Back: This state writes the 128-bit block to memory using the address composed from the tag and cache index. We remain in this state waiting for the Ready signal from memory. When the memory write is complete, the FSM goes to the Allocate state.
Allocate: The new block is fetched from memory. We remain in this state waiting for the Ready signal from memory. When the memory read is complete, the FSM goes to the Compare Tag state.
9.Fully associative cache introduction
10.Direct-mapped cache introduction


11.Set-associative introduction
12.Fully-associative introduction


13.Analyzing cache performance