5.1.Parallelism via Instruction
\(5.1.\)Parallelism via Instructions
1.Pipelining
Exploiting the potential parallelism among instructions is called instruction-level parallelism.
The first is increasing the depth of the pipeline to overlap more instructions.
We also need to reblance the remaining steps so they are the same length.
Another approach is to replicate the internal components so that it can launch multiple instruction in every pipeline stage. The general name of this approach is multiple issue.
2.Multiple issue processor
There are two main ways to implement a multiple-issue processor, with the major difference being the division of work between the compiler and the hardware. One is called static multiple issue and the other dynamic multiple issue.
There are two primary distinct responsibilities within a multiple-issue pipeline:
Packaging instructions into issue slots. It refers to the position from which instructions could issue in a given clock cycle. In dynamic multiple issue, it is normally dealt with at runtime by processor.
Dealing with data and control hazards. The compiler handles it statically. In contrast, most dynamic issue processors attempt to alleviate them using hardware techniques operation at execution time.
3.Speculation concepts(extracted from textbook)
Speculation is an approach that allows the compilator/processor to "guess" about the properties of an instruction. Any speculation mechanism must include both a method to check if the guess was right and a method to unroll or back out the effects of the instructions that were executed speculatively.
Speculation may be done in the compiler or by the hardware. For example,the compiler can use speculation to reorder instructions, moving an instruction across a branch or a load across a store. The processor hardware can perform the same transformation at runtime using techniques we discuss later in this section.
The recovery mechanisms used for incorrect speculation are rather different. In the case of speculation in software, the compiler usually inserts additional instructions that check the accuracy of the speculation and provide a fix-up routine to use when the speculation is wrong. In hardware speculation, the processor usually buffers the speculative results until it knows they are no longer speculative. If the speculation is correct, the instructions are completed by allowing the contents of the buffers to be written to the registers or memory. If the speculation is incorrect, the hardware flushes the buffers and re-executes the correct instruction sequence. Misspeculation typically requires the pipeline to be flushed, or at least stalled, and thus further reduces performance.
Speculation introduces one other possible problem: speculating on certain instructions may introduce exceptions that were formerly not present. For example, suppose a load instruction is moved in a speculative manner, but the address it uses is not within bounds when the speculation is incorrect. The result would be that an exception that should not have occurred would occur. The problem is complicated by the fact that if the load instruction were not speculative, then the exception must occur! In compiler-based speculation, such problems are avoided by adding special speculation support that allows such exceptions to be ignored until it is clear that they really should occur. In hardware-based speculation, exceptions are simply buffered until it is clear that the instruction causing them is no longer speculative and is ready to complete; at that point, the exception is raised,and normal exception handling proceeds.
4.Static multiple issue
Static multiple-issue processors all use the compiler to assist with packaging instructions and handling hazards. In a static issue processor, we can think of the set of instructions issued in a given clock cycle called issue packet. And it's useful to think of the issue packet as a single instuction allowing weveral operations in certain predefined fields.
When it comes to the certain instructions:
We require that the instructions be paired and aligned on a 64-bit boundary.
If on instruction of the pair cannot be used, we require that it be replaced with nop.
However, the overlapping of instructions increase the relative performance loss from data and control hazards.
For example, in our simple five-stage pipeline, loads have a use latency of one clock cycle, which prevents one instruction from using the result without stalling. In the two-issue, five-stage pipeline the result of a load instruction cannot be used on the next clock cycle. This means that the next two instructions cannot use the load result without stalling.
An important compiler technique to get more performance from loops is loop unrolling:
- Say we are going to deal with this program:
1 | for (int i = 0; i < 8; i++) { |
1 | Loop: |
We can do this iteration part for more times:
1 | for (int i = 0; i < 8; i += 4) { |
1 | Loop: |
This operation has the following advantages:
Reduce cycle control overhead: cycle control operations are less frequent when the cycle is expanded. In the above example, the loop control operation is reduced from one generation per generation to one generation per four.
Increase instruction level parallelism: the more instructions expanded, the compiler can better schedule these instructions, improve parallelism.
Reduced branch prediction failure: the probability of branch prediction failure is reduced due to the reduction in the number of branch instructions and the frequency of loop control operations.
During the unrolling process, the compiler introduce additional registers. The goal of the process, called register renaming, it to eliminate dependences that are not true data dependences, but could either lead to potential hazards or prevent the compiler from flexibly scheduling the code.
5.Dynamic multiple-issue processor
Dynamic multiple-issue processors are also known as superscalar processors.
Many superscalars extend the basic framework of dynamic issue decisions to include dynamic pipeline scheduling. Dynamic pipeline scheduling chooses which instructions to execute in a given clock cycle while trying to avoid hazards and stalls.
Dynamic pipeline scheduling chooses which instructions to execute next, possibly reordering them to avoid stalls. The pipeline is divided into three major units: an instruction fetch and issue unit, multiple functional units, and a commit unit.
The first unit fetch instructions, decodes them and sends them to corresponding function unit for execution.
Each function unit has buffers called reservation stations, which hold the operands and the operation. As soon as the buffer contains all its operands and the functional unit is ready to execute, the result calculated. The result is sent to any reservation stations waiting for this particular result and the commit unit.
The commit unit buffers the result until it's safe to put the result into the register file/memory. The buffer in the commit unit, often called the reorder buffer, is also used to supply operands.
Once a result is committed to the register file, it can be fetched directly from there like in a normal pipeline.
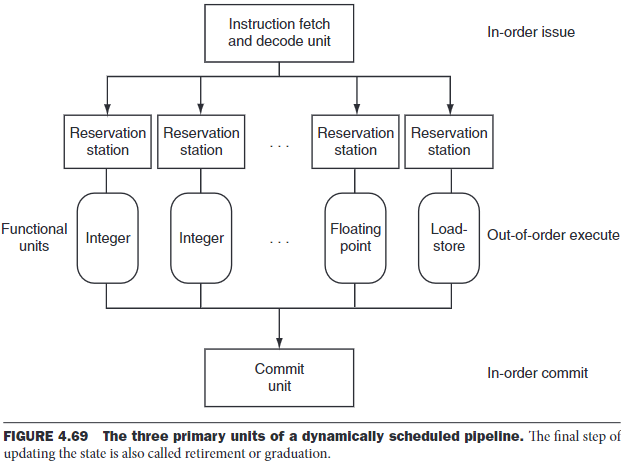
If an operand is not in the register file or reorder buffer, it must be waiting to be produced by a functional unit. The name of the functional unit that will produce the result is tracked. When that unit eventually produces the result, it is copied directly into the waiting reservation station from the functional unit bypassing the registers.
We may think of a dynamically scheduled pipeline as an out-of-order execution. To make programs behave as if they were running on a simple in-order pipeline, the instruction fetch and decode unit is required to issue instructions in order, which allows dependences to be tracked, and the commit unit is required to write results to registers and memory in program fetch order. This conservative mode is called in-order commit. Hence, if an exception occurs, the computer can point to the last instruction executed.