5.2.SIMD, MIMD, SIMD, SPMD and Vector
\(5.2.\)SIMD, MIMD, SIMD, SPMD and Vector
1.Basic concepts

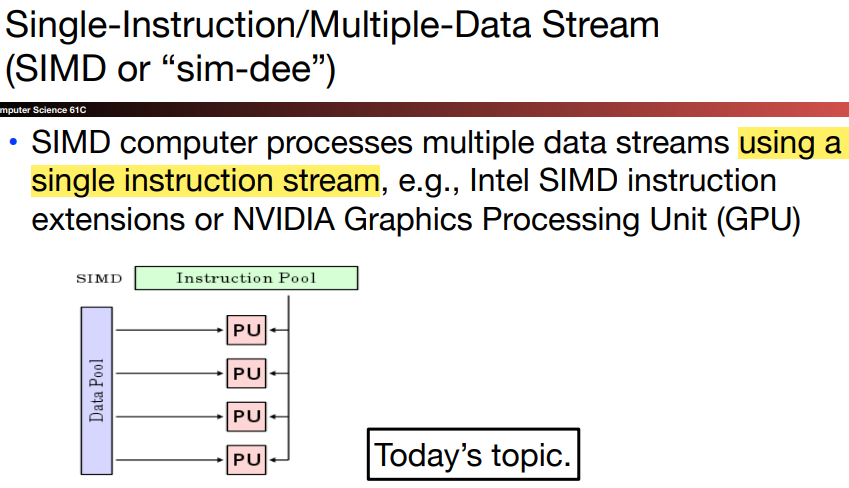
In SIMD, all the parallel execution units are synchronized, and they all respond to a single instruction that emanates from a single program counter.
Each execution unit has its own address register, and so have different data address.
The original motivation behind SIMD was to amortize the cost of the control unit over execution units. The SIMD can also save instrustion bandwidth and space: SIMD needs only one copy of the code that is being simultaneously executed.
Since the instruction is single, SIMD works best when dealing with identically structured data, which is called data-level parallelism, e.g., for loop.
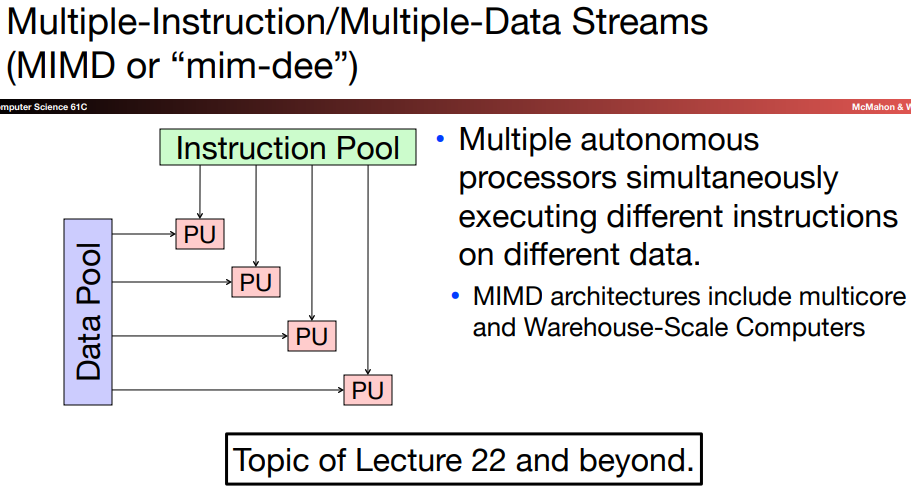
SPMD: The programmer write a single program that runs on all processors of a MIMD computer, relying on conditional statements when different processors should execute distinct section of code.
The SIMD computers operate on vectors of data.
2.Vector
\(a.\)Concepts and characteristics
The basic philosophy of vector architecture is to collect data elements from memory, put them in order into a large set of registers, and operate on them sequentially in registers using pipelined execution units.
- A key feature of vector architectures is a set of vector registers.
Take the following expression as an example(it's called DAXPY loop):
\[ Y = a \times X + Y \]
In conventional RISC-V, it's written as below:

By using vector, we can write it in a more concise way:

No only does the code reduce the dynamic instruction bandwidth, but also the pipeline stalls are required only once per vector operation, rather than once per vector element.
Vector also holds the following characteristic:
The compiler indicates that the computation of each result in the vector is independent. So compiler doesn't have to check for data hazards within an instruction.
Since the element in a vector is adjacent, the cost of the latency to main memory is seen only once for the entire vector.
Because a complete loop is replaced by a vector instruction whose behaviour is predetermined, control hazards are nonexistent.
\(b.\)Related architecture
- Unlike multimedia extensions, the number of elements in a vector operation isn't in the opcode but in a separate register.
This means different versions of the vector architecture can simply be implemented by changing the contents of the register, thus retain binary compatibility.
- The parallel semantics of a vector instruction allows using a deeply pipelined functional unit to execute vector operations:
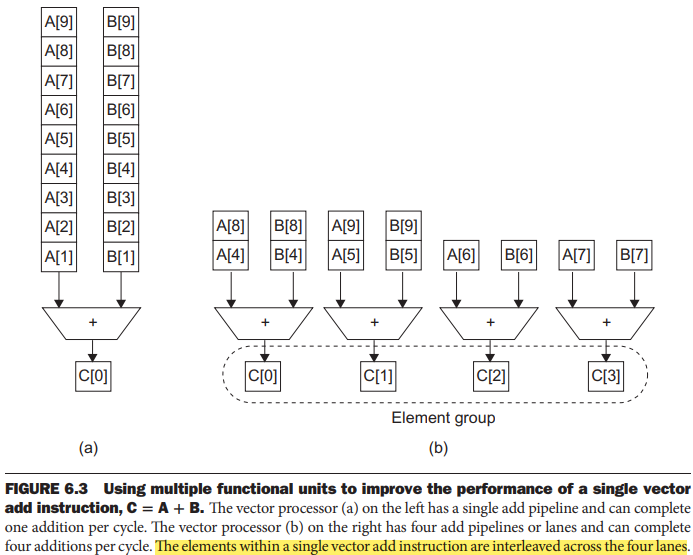
Vector arithmetic instructions only allow element N of one vector register to take part in operations with element N from other vector registers, and the structure is called vector lanes:
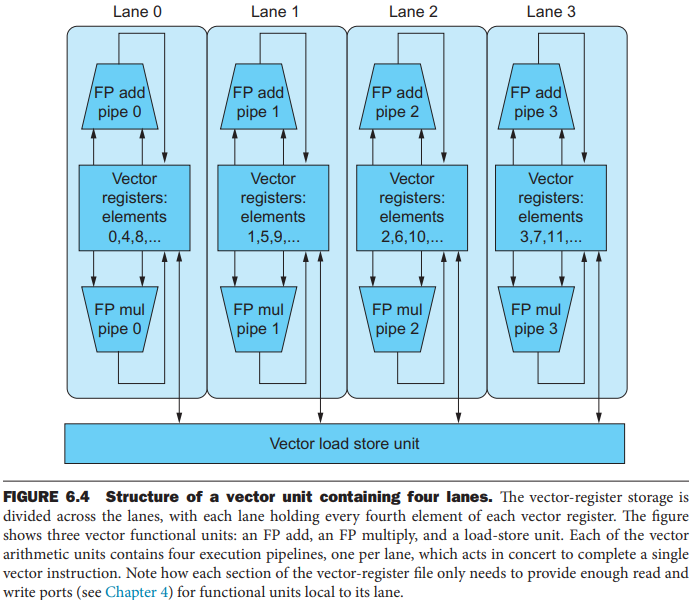
As with a traffic highway, we can increase the peak throughput of a vector unit by adding more lanes.