5.8.Loop Unrolling
\(5.8.\)Loop Unrolling
Loop unrolling can improve performance in two ways.
It reduces the number of operations that do not contribute directly to the program result, such as loop indexing and conditional branching.
It exposes ways in which we can further transform the code to reduce the number of operations in the critical paths of the overall computation.
1 | /* 2 x 1 loop unrolling */ |
The performance of different unrolling is as below:
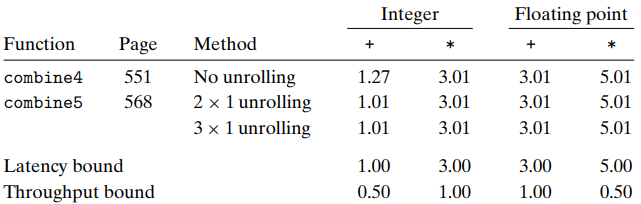
We see that the CPE improves little when \(k \geq 2\). To understand this, consider the case when \(k=2\):
1 | # Inner loop of combine5. data_t = double, OP = * |
The vmulsd instructions each get translated into two
operations: one to load an array element from memory and one to multiply
this value by the accumulated value. The data-flow representation of the
program is as below:
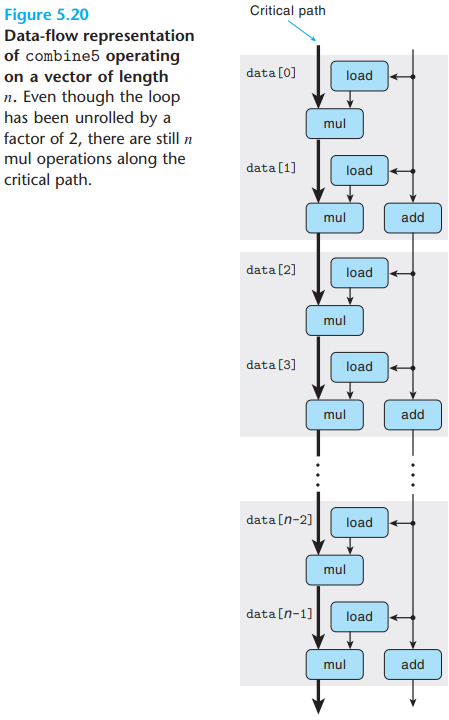
There's still a critical path of \(n\)