5.9.Enhancing Parallelism
5.9.Enhancing Parallelism
1.Multiple Accumulator
\(a.\)Basic idea
Assume that \(P_n\) represents the product of elements \(a_0,a_1, \cdots ,a_{n-1}\):
\[ P_n = \prod ^{n-1} _{i=0} a_i \]
We can rewrite this as \(P_n=PE_n \times PO_n\):
\[ PE_n = \prod ^{ {n \over 2} -1} _{i=0} a_{2i} \]
\[ PO_n = \prod ^{ {n \over 2} -1} _{i=0} a_{2i+1} \]
By using this method, we use both two-way loop unrolling and two-way parallelism. We refer to this as \(2\times 2\) loop unrolling:
1 | /* 2 x 2 loop unrolling */ |
The performance of this program is as below:
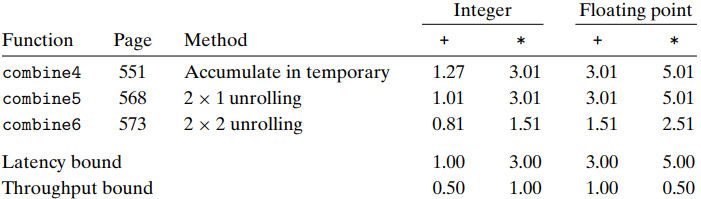
We can see that we improve the performance by a factor of around 2. Most significantly, we have broken through the barrier imposed by the latency bound. The processor no longer needs to delay the start of one sum or product operation until the previous one has completed.
The data-flow representation of combine6 is as
below:
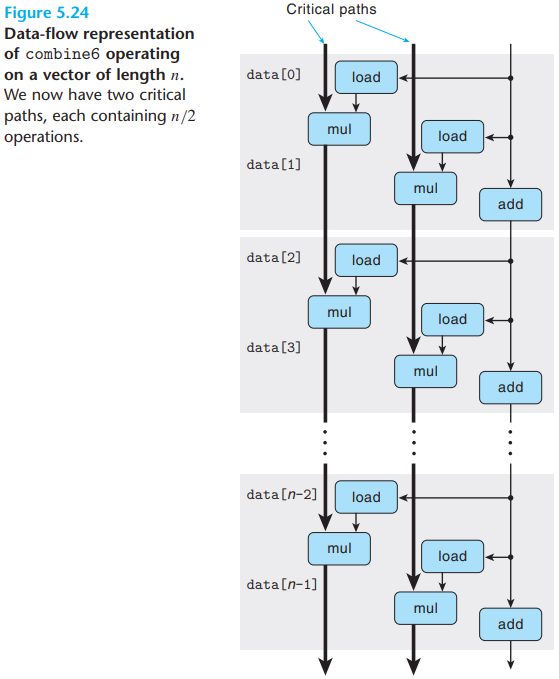
There are two critical paths, and each of these contains only \(n \over 2\) operations, thus leading to a CPE of around 5.00/2 = 2.50.
\(b.\)General analysis
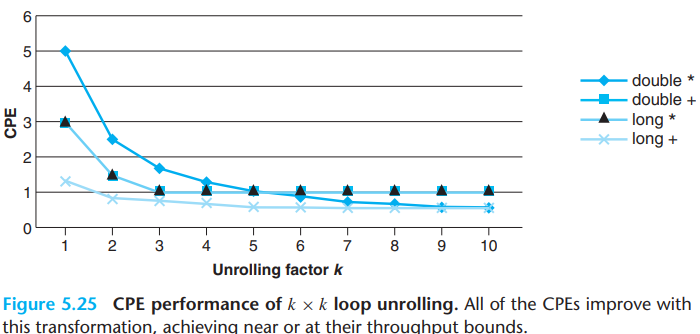
In general, a program can achieve the throughput bound for an operation only when it can keep the pipelines filled for all of the functional units capable of performing that operation. For an operation with latency \(L\) and capacity \(C\), this requires an unrolling factor \(k \geq C \cdot L\).
- For example, floating-point multiplication has \(C=2\) and \(L=5\), necessitating an unrolling factor of \(k \geq 10\).
In performing the \(k \times k\) unrolling transformation, we must consider whether it preserves the functionality of the original function.
Two's-complement arithmetic is commutative and associative, so the unrolling transformation will get identical result.
Floating-point multiplication and addition are not associative, so we may get different result.
2.Reassociation Transformation
\(a.\)Basic idea
By simply change the code of \(k \times 1\) loop unrolling, we can reach better performance. For example, the code:
1 | acc = (acc OP data[i]) OP data[i+1]; |
can be changed into:
1 | acc = acc OP (data[i] OP data[i+1]); |
The performance of the code is nearly the same as \(2 \times 2\) loop unrolling: