5.12.Understanding Memory Performance
\(5.12.\)Understanding Memory Performance
1.Store Performance
A series of store operations cannot create a data dependency. Only a load operation is affected by the result of a store operation, since only a load can read back the memory value that has been written by the store.
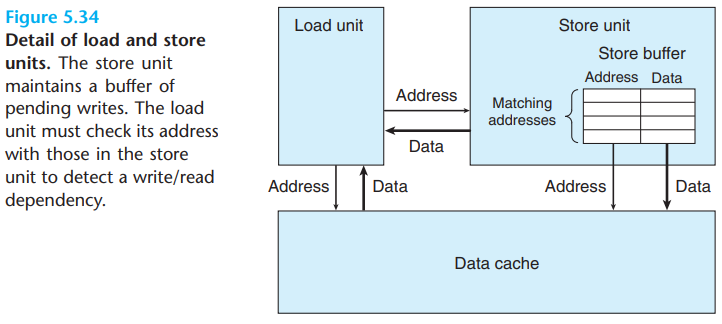
The store unit includes a store buffer containing the addresses and data of the store operations that have been issued to the store unit, but have not yet been completed, where completion involves updating the data cache.
This buffer is provided so that a series of store operations can be executed without having to wait for each one to update the cache.
2.Load and Store Operations
\(a.\)Different types of load & store
1 | /* Write to dest, read from src */ |
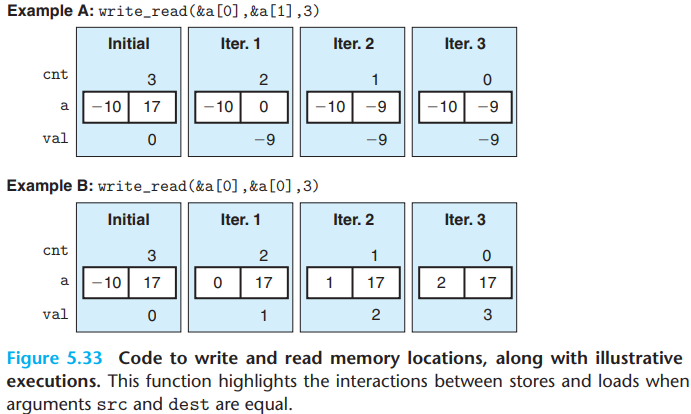
In Example A, the result of the read from
srcis not affected by the write todest, and the iterations gives a CPE of 1.3.In Example B, each load by the pointer reference
*srcwill yield the value stored by the previous execution of the pointer reference*dest.
This example illustrates a phenomenon we will call a write/read dependency—the outcome of a memory read depends on a recent memory write.
The CPE of Example B is 7.3, The write/read dependency causes a slowdown in the process.
The reason of the slowdown can be illustrated in the following data-flow representation:
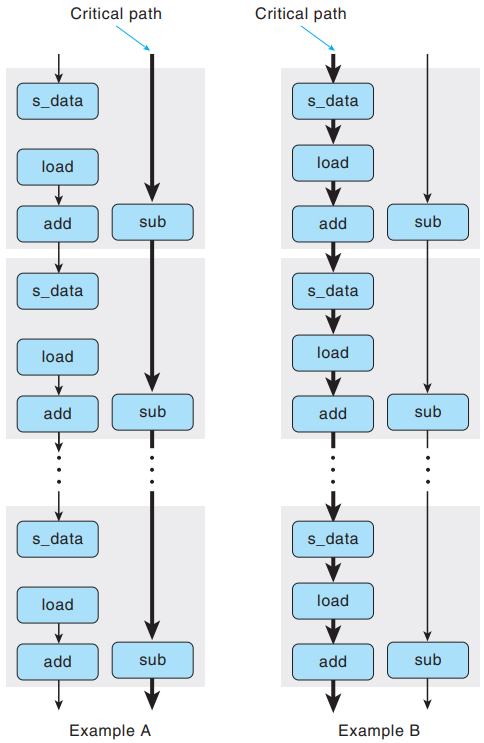
For the case of Example A, with differing source and destination addresses, the load and store operations can proceed independently, and hence the only critical path is formed by the decrementing of variable cnt, resulting in a CPE bound of 1.0.
\(b.\)Load performance
When a load operation occurs, it must check the entries in the store buffer for matching addresses. If it finds a match, it retrieves the corresponding data entry as the result of the load operation.
Take the following assembly code as an example:
1 | # Inner loop of write_read |
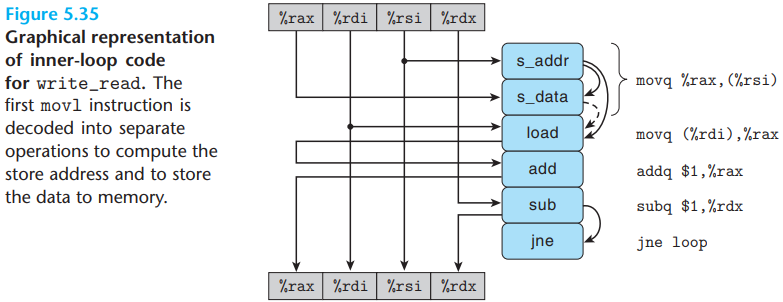
The
s_addrinstruction computes the address for the store operation, creates an entry in the store buffer, and sets the address field for that entry.The
s_dataoperation sets the data field for the entry.
The arcs on the right of the operators denote a set of implicit dependencies for these operations:
For instruction
movq (%rdi), %rax, the load operation must check the addresses of any pending store operations, creating a data dependency between it and thes_addroperation.- If the two addresses match, the load operation must wait until the s_data has deposited its result into the store buffer, but if the two addresses differ, the two operations can proceed independently.