适配层
适配层
1. 提示
零样本学习与少样本学习
概述
GPT-3/4 这样的大型语言模型,展现出了一种惊人的新能力:
- 零样本学习 (Zero-shot):不需要给它任何范例,只需用自然语言清晰地描述任务,它就能直接执行。
- 少样本学习 (Few-shot / In-context Learning):只需在指令中提供几个(通常是1到几十个)范例,模型会立刻学习任务的模式并开始执行,这个过程不需要重新训练模型。
这些强大的“学习”能力并不是随着模型参数量的增加而平滑提升的,而是在模型规模达到某个巨大的临界点后,才突然“涌现”出来。
零样本学习
零样本学习具有如下的特点:
- 无样本 (no examples):执行任务前,不需要给模型看任何已经完成的例子。
- 无梯度更新 (no gradient updates):完全不调整模型的内部参数(权重),也就是说,模型本身没有被“训练”或“微调”。
我们的语言模型的核心功能是给定一段文本,预测下一个最可能出现的词(Token),通过将任务转换成一个序列预测问题、让预测的结果正好是问题的解,可以让模型在无样本学习的条件下解决我们的问题。有如下两种常见的做法:
- 构建问答/指令格式
- 例如:
Passage: Tom Brady... Q: Where was Tom Brady born? A: ...我们把文章、问题和答案的开头A:拼接成一个长字符串。模型看到A:之后,它的任务就是预测最有可能跟在后面的文字,而这个预测结果自然就是问题的答案。
- 例如:
- 比较不同序列的概率
- 例如 Winograd Schema 挑战:
The cat couldn't fit into the hat because it was too big. it 指的是 cat 还是 hat?这个问题可以转化为比较两个句子的概率:P(...because the cat was too big)的概率P(...because the hat was too big)的概率
- 模型会计算出哪个句子更通顺、更符合逻辑(即概率更高)。在这个例子里,模型会发现“因为猫太大了”比“因为帽子太大了”的概率更高,从而正确地判断 it 指的是 cat。
- 例如 Winograd Schema 挑战:
少样本学习
少样本学习,也称为上下文学习 (In-context Learning),它在向模型提出真正的任务之前,先在提示词 (Prompt) 中给出几个完整的“任务范例”。这个过程同样没有梯度更新,模型只是在“上下文”中临时学习,并不会永久改变。
高级提示
与微调不同,提示 (Prompting) 是在模型推理时提供信息。下面我们讲解一些高级的提示。
思维链提示
如果我们在提示词的范例只提供最终答案时,模型学会的是模仿“直接给出答案”这个格式,而不是学习如何推理,它没有理解问题背后的逻辑步骤。:

通过在范例中展示如何一步步思考,我们引导模型在回答新问题时,也模仿这个“思考过程”,而不是直接跳到结论。这迫使它分解问题、执行正确的计算:

零样本思维链
思维链已经很强大了,但还需要提供一个完整的推理范例。研究人员很快发现,思维链中的范例也可以省掉。我们只需要在问题的结尾加上一句简单的指令:“让我们一步一步地思考。 (Let's think step by step.)

2. 参数高效微调
核心思想
参数高效微调 (Parameter-Efficient Fine-tuning, PEFT)的核心思想是:在微调时,我们不需要更新模型的所有参数,而是冻结 (freeze) 绝大部分原始参数,只调整其中极小一部分(或者添加一小部分新的“适配器”参数)。
研究发现,现在最先进的大模型是严重过参数化的。这意味着模型中有大量的“冗余”参数。这意味着你不需要改变所有参数来教它一个新任务,只需要进行小范围的、精确的调整就足够了。
稀疏子网络方法
概述
想象一个巨大的、拥有数十亿连接的神经网络。当我们想让它完成一个新任务时,我们真的需要动用整个网络吗?稀疏子网络 (Sparse Subnetworks) 的思路认为,我们不需要。网络中其实隐藏着一条“最优路径”(即子网络),我们只需要找到并强化这条路径,就可以高效地完成任务,而网络的其他部分可以保持原样。
而剪枝 (Pruning) 就是我们用来寻找这条“最优路径”的工具。
剪枝的相关概念
剪枝是实现稀疏性的方法:剪枝就是将网络中不重要的连接识别出来并移除(设置为零)的过程。
权重大小是网络连接重要性最常见的判断标准。我们通常会剪掉那些绝对值最小(最接近零)的权重。
从数学上看,剪枝可以被视为给模型的每个权重应用一个由0和1组成的掩码 (mask)。如果掩码上对应位置是1,权重就被保留;如果是0,权重就被设为零,相当于被“剪掉”了。通过这种方式,我们可以从原始的密集网络中,雕刻出了一个更小的子网络。
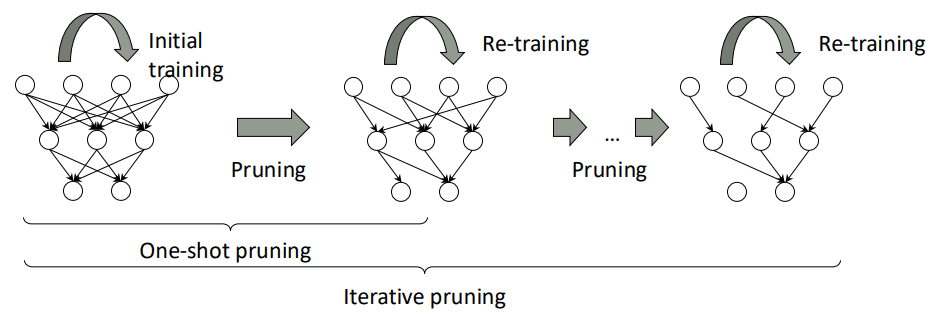
剪枝流程
剪枝主要有下面两种流程:
- 一次性剪枝 (One-shot Pruning):
- 初始训练:正常训练模型。
- 剪枝:一次性剪掉大量低权重的连接。
- 重训练 (Re-training):固定网络的结构(被剪掉的连接不再恢复),然后继续训练那些被保留下来的权重,让它们去补偿被移除部分的功能。
- 迭代剪枝 (Iterative Pruning):这是一个循环往复、更精细化的过程,也是现在更常用、效果更好的方法。
- 循环:训练一会 → 剪掉一小部分权重 → 再训练一会 → 再剪掉一小部分 → ... 如此循环。
- 这种渐进式的方法让网络有时间慢慢适应结构的变化,性能通常比一次性剪枝要好。
剪枝与微调的统一
我们可以将剪枝看作是向现有模型的参数 添加一个特定于任务的向量 :
我们可以将现有权重与二元掩码相乘,以将被剪枝的权重设置为 0:
差异剪枝
通常,我们根据权重最终的绝对值大小来决定是否剪枝。也就是 的大小。
而差异剪枝(Diff Pruning)不看权重的最终大小,而是看权重在微调过程中的变化量 的绝对值大小,即 。
这个剪枝方法的逻辑如下:如果一个预训练好的权重,在为了适应新任务而进行的微调中,几乎没有发生任何变化(即 很小),那就说明这个权重对于完成这个新任务并不关键。即使它本身的初始值 很大,它对"适配"这个新任务的贡献也很小。因此可以把它剪掉。
彩票假说
彩票假说 (The Lottery Ticket Hypothesis) 为“为什么剪枝可行”提供了非常深刻的解释。它的核心内容如下:在一个巨大的、随机初始化的神经网络中,必然隐藏着一个微小的子网络。如果我们能找到这个子网络,并将它单独拿出来从头开始训练,它能达到与原始完整网络相当甚至更好的性能,而且训练速度更快。这个幸运的子网络就被称为“中奖彩票” (Winning Ticket)。
这个假说在 BERT 这样的预训练模型中也得到了验证。这意味着,一个庞大的预训练模型,本身就包含了能解决各种不同下游任务的“中奖彩票”。当我们对 BERT 进行微调时,本质上就是在寻找适用于当前任务的那个子网络。
低秩自适应
概述
低秩自适应 (Low-Rank Adaptation, LoRA) 是一种更高效的参数微调方法,其核心思想如下:
- 在微调过程中,我们不必为每个任务学习一整套巨大的参数更新 ,而是可以用一个尺寸小得多的参数集 “编码”或“生成”这个巨大的 。也就是说, 是由 计算得出的,并且 的参数数量远小于 ()。
- 这样,寻找最优 的任务,就转变成了寻找最优的、小得多的 的任务。优化目标函数也相应地变成了在 上进行最大化。
LoRA的理论基础是:有研究发现,在模型适应新任务时,其权重的变化(也就是)具有“低内在秩 (low intrinsic rank)”的特性。通俗地讲,就是这些巨大的变化矩阵,其实可以用更简单的、信息量更集中的小矩阵来表示。
工作流程
LoRA的具体工作流程如下:
- 假设 是预训练模型中的一个权重矩阵。
- 我们不直接更新 ,而是给它加上一个由两个小矩阵相乘得到的更新量 ΔW。
- 这个更新量被约束为一个低秩分解形式:。
- 是一个 维的矩阵, 是一个 维的矩阵。
- 关键在于 (秩) 是一个远小于 和 的数 ()。
- 是一个超参数(需要手动设置的数值),它像一个缩放因子,用来平衡预训练知识(来自 )和新学到的任务知识(来自 )之间的关系。
- 在训练时,原始的权重 保持不变,只有 和 这两个小矩阵的参数是可训练的。因为 很小,所以 和 的总参数量远小于 。
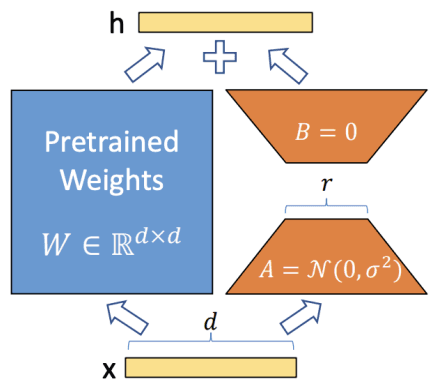
矩阵 通常用高斯分布随机初始化,而矩阵 初始化为全零。这意味着在训练刚开始时, 的结果是 0,旁路不起任何作用,整个模型的输出完全等同于原始预训练模型。随着训练的进行, 和 才慢慢学习到对这个特定任务有用的“残差”或“修正量”。
LoRA的优点
LoRA 具有如下的优点:
- 参数高效
- 无额外的推理延迟 (No additional inference latency):在训练时,我们需要保留旁路结构。但在部署用于推理时,我们可以把学习到的 矩阵直接加回到原始权重 上,即 。这样模型在推理时就只有一个矩阵 ,其计算路径和原始模型完全一样,因此不会增加任何计算时间或延迟。
- 任务切换轻便:如果要切换到另一个任务,我们不需要加载一个全新的大模型,而是只需要用当前任务的 替换掉上一个任务的 即可。这个操作可以表示为 ,只是简单的矩阵减法和加法,非常快速和高效。
这意味着我们可以只保留一个共享的、巨大的基础模型,并为每个任务存储一对非常小的 和 矩阵。
LoRA 通常被应用于 Transformer 模型中的自注意力模块的权重矩阵上,因为这些部分被认为对模型适应新任务最为关键。
3. 从输入角度的适配
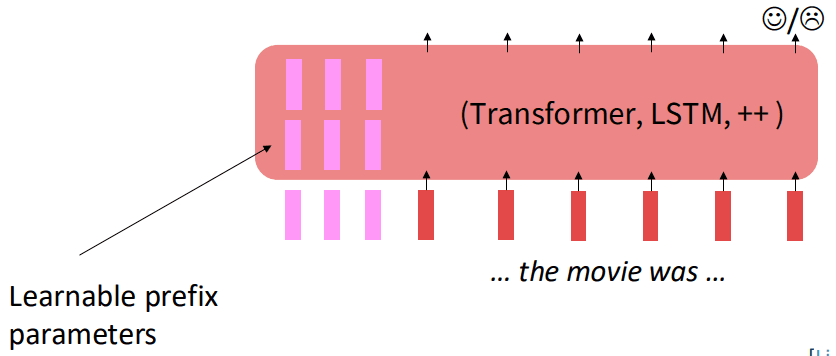
前缀微调
前缀微调 (Prefix-Tuning) 会完全冻结预训练好的语言模型的全部参数。然后,它在模型输入的前面添加一小段可训练的参数,这段参数被称为前缀 (prefix)。在训练过程中,只有这个前缀的参数会被更新。
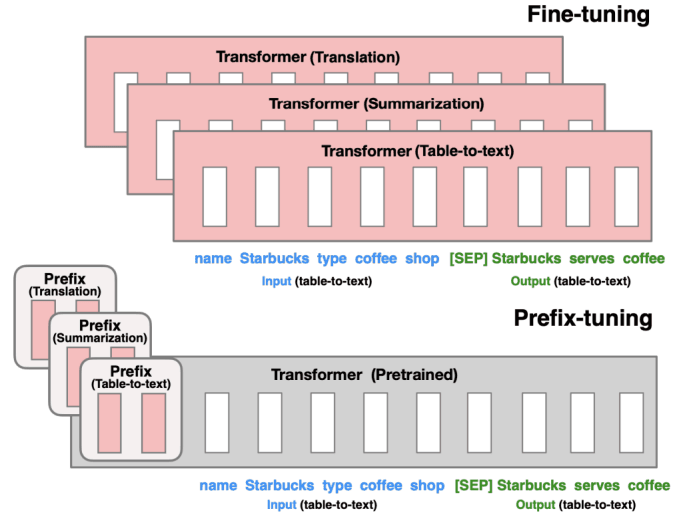
前缀并不是由人类可读的真实词汇组成的,而是一系列连续的、任务专属的向量,可以把它们想象成一些“虚拟的词 (virtual tokens)”。这些可训练的前缀向量,在Transformer模型的每一层中,都添加到键和值的序列前面。这样,这个前缀就能在模型的每个计算层面上影响注意力机制的计算,从而更有效地引导模型的行为以适应特定任务。
提示词微调
在提示词微调中,我们在输入文本前加入一个可调节的软提示,训练的目标是学习这个软提示的参数。
与我们手动设计的、人类可读的“硬提示”不同,软提示是一些可学习的、连续的向量。它们被添加到输入文本的前面,就像一些特殊的“虚拟”词一样。在训练时,我们只更新这些虚拟Token的向量表示,而模型主体完全不动。
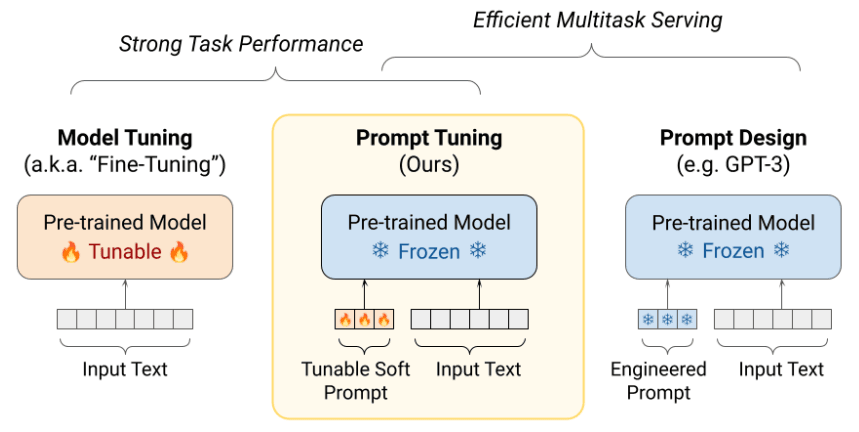
对于每个新任务,我们只需要学习并存储一个非常小的软提示,这使得我们可以用同一个基础模型,通过**切换不同的“软提示”**来高效地服务于成百上千个任务。
不过需要注意:提示词微调的效果和模型规模由很大关系。
4. 适配
适配的功能性视角
适配可以看作是函数组合。它通过引入新的、针对特定任务的函数,来增强或改变原始模型的功能:
这种思想在多任务学习中非常常见,不同任务的模块(函数)可以被组 合起来使用。
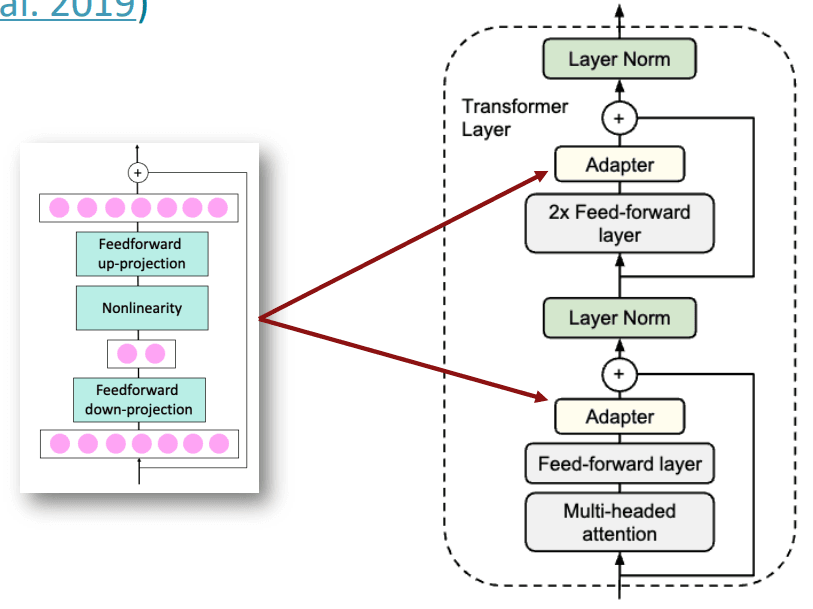
适配器
我们可以在预训练模型的层与层之间插入一些新的、小型的神经网络模块,也就是适配器(Adapters),从而让模型适配下游任务。在训练时,只更新这些模块的参数,而预训练模型的主体同样保持冻结。
一个典型的适配器模块包含两个前馈神经网络层和一个非线性激活函数:
- 下投影 (down-projection) :一个全连接层,它会将输入的高维特征向量(维度为 )映射到一个低维空间(维度为 )。这起到了压缩信息、减少参数量的作用。
- 非线性激活
- 上投影 (up-projection) : 这是另一个全连接层,它会将低维向量重新映射回原始的高维空间(维度为 )。
这个结构也叫作瓶颈结构 (Bottleneck)。
除了适配器, 预训练模型还包含残差连接部分。这非常关键,它保证了即使适配器在训练初期什么都没学到,信息流也能无损地通过原始路径传递,保证了训练的稳定性:
适配器通常被放置在 Transformer 层中的两个关键位置:
- 多头注意力层 (Multi-head Attention) 之后。
- 前馈神经网络层 (Feed-forward layer) 之后。
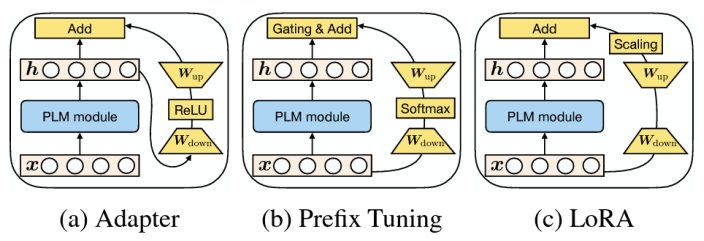
5. 不同适配方法的统一性
适配器、前缀微调、LoRA这些高效适配方法,本质上都可以被统一成一个相似的数学形式。它们都是通过某种方式修改模型在某一层的隐藏状态 :
6. 知识蒸馏
除了上面这些模型适配技术,知识蒸馏 (Knowledge Distillation)也是一个常用的技术。它的核心思想是将一个更大、更强的教师模型 (Teacher Model)所具备的知识,迁移到一个更小、更轻量的学生模型 (Student Model)中。
知识蒸馏的具体流程如下:
- 让教师模型和学生模型同时处理相同的数据。
- 训练学生模型,使其输出不仅要接近真实标签(hard label),还要模仿教师模型的输出概率分布(soft label)。这样,学生模型就能学到教师模型对于数据“如何思考”的深层逻辑。
Comments