卷积神经网络
• 13 min read • 2531 words
Tags: Deep Learning Ma-Le
Categories: Machine Learning
卷积神经网络
1. 概述
基本概念
卷积神经网络 (Convolutional Neural Networks) 的灵感来源于图像处理中的“边缘检测器”:
- 局部性 (Locality):一个边缘检测器每次只观察图像的一小部分区域。
- 平移不变性 (Translation Invariance):无论在图像的哪个位置,边缘检测的计算方式都是相同的。
- 可学习性 (Learnable):这是CNNs最核心的创新——我们不再手动设计这些边缘检测器,而是让网络通过数据自己“学习”出这些检测器的最佳参数。
基于这些内容,CNN 被设计如下:
- 局部连接性 (Local Connectivity):隐藏层中的一个单元(神经元)不再连接到前一层的所有单元(即整个图像),而是仅仅连接到一个小的局部区域,这个区域被称为“感受野”(receptive field)。这极大地减少了连接数量,从而显著提升了训练和分类的速度。
- 权重共享 (Shared Weights):一组隐藏单元共享同一套权重参数。这套共享的权重被称为滤波器 (filter),也叫卷积核 (kernel) 或掩码 (mask)。这个卷积核会像一个滑动的窗口,在整个图像的每一个局部区域(patch)上进行相同的运算。当一个卷积核滑过整个图像后,会生成一张激活图 (activation map)。激活图上的每一个值,都代表了该卷积核在图像对应位置的“激活”程度(即特征的匹配程度)。
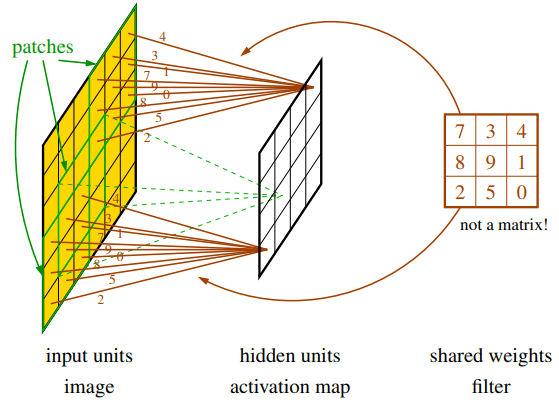
现实中的 CNN 的结构通常会更复杂一些,添加了如下的组件:
- 多滤波器:一个卷积层通常会学习多个不同的滤波器。每个滤波器负责检测一种特定的特征(如一个滤波器学习检测水平边缘,另一个学习检测垂直边缘,还有一个可能学习检测绿色斑点等)。每个滤波器都会生成一张独立的激活图。
- 通道 (Channel):一张激活图就是一个通道。因此,如果一个卷积层有
C_out个滤波器,它的输出就会有C_out个通道。 - 多输入通道:同样,输入数据也可以是多通道的。最典型的例子就是彩色图像,它天然就包含红(R)、绿(G)、蓝(B)三个通道。
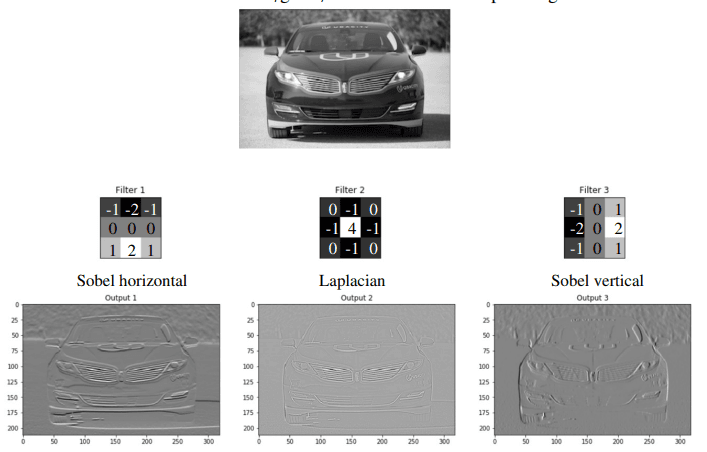
CNN 的权重共享设计具有如下的优势:
- 参数数量急剧下降,使得模型更轻量。
- 有效的正则化:因为一个权重被用于图像的很多不同位置,它不太可能为了拟合某个局部的噪声而变得异常大,从而提高了模型的泛化能力。
- 特征学习的效率:如果一个滤波器在图像的某个部分学会了检测“边缘”这个特征,它就能自动地在图像的所有其他部分检测边缘,因为它被应用到了每一个位置。CNNs正是利用了图像、音频等数据中这种普遍存在的重复结构。
一个实际的例子
Yann LeCun的LeNet-5是一个成功的 CNN 案例,它拥有6个隐藏层的深度网络,交替使用了:
- 卷积层 (Convolutional Layers):用于特征提取。
- 池化/子采样层 (Pooling/Subsampling Layers):用于降低图像尺寸,进一步减少参数并提供一定程度的平移不变性。
- 全连接层 (Fully-connected Layers):在网络末端,用于根据提取到的高级特征进行最终的分类。
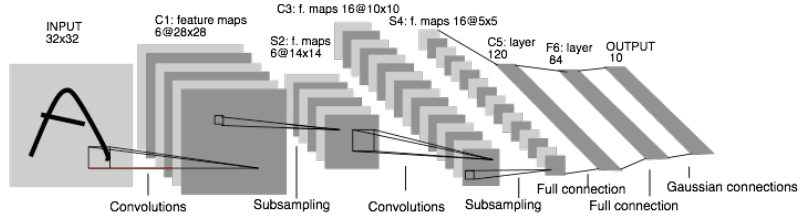
2. CNN 相关参数计算
我们考虑一个卷积层 ,首先定义如下的变量:
- : 第 层(即当前层的输入)的通道数
channels in。 - : 第 层(即当前层)的输出通道数
channels out。这个数量也等于当前层所拥有的滤波器数量。 - : 卷积核的边长(假设为 的方形卷积核)。
- : 输入图像或输入特征图的尺寸。
则:
- 每个滤波器的权重数量:
- 整个卷积层的权重数量::即“每个卷积核的权重数量”乘以“卷积核的总数”。
- 输出单元的数量::即“卷积核数量”乘以“特征图尺寸”。
3. 信息压缩与下采样
在像 LeNet-5 这样的网络末端,我们需要将庞大的图像信息最终压缩到只有10个输出单元(对应10个数字类别)。经验表明,最好的方法是通过一系列层来逐步、缓慢地压缩信息,而不是将一个非常大的隐藏层直接连接到小小的输出层。
池化
池化 (Pooling) 的核心思想是用一个值来概括一个小邻域内的信息,从而降低特征图的尺寸。有最大池化和平均池化两种形式。
- 最大池化在一个小的窗口内,只取其中的最大值作为输出。
最大池化保留了每个小区域内最显著的特征。这相当于在问:“在这个小区域里,我最想找的那个特征出现了吗?它的响应强度有多大?”
- 平均池化与最大池化类似,但它不是取最大值,而是计算窗口内所有数值的平均值作为输出。
池化操作是固定的(取最大或取平均),因此它没有任何需要通过训练学习的参数。这使得它计算开销很小。但在训练时,梯度仍然需要通过池化层进行反向传播。对于最大池化,梯度只会传给那个被选为最大值的单元。
步幅卷积
步幅卷积 (Strided Convolution) 是另一种实现下采样的方法,它将下采样和卷积操作合二为一:它让卷积核每次移动超过1个像素(如步长为2)。
全连接层
在经过多轮的“卷积 激活 池化/步幅卷积”操作后,我们得到了一组高度抽象的特征图。在网络的最后阶段,我们需要根据这些特征进行分类。这一步即由全连接层来完成:
- 展平 (Flatten):全连接层的第一步是将最后一个卷积/池化层输出的多维特征图(如尺寸为 7x7x512)“压平”或“展平”,变成一个一维的长向量(长度为 77512 = 25088)。
- 连接与分类:这个长向量随后被送入一个或多个标准的全连接层(也叫密集层,Dense Layer)。
- Softmax激活函数:在最后的分类层,通常使用 Softmax 激活函数。它的作用是将输出层的数值转换成一个概率分布,每个数值代表输入图像属于某个特定类别的概率(所有概率值相加为1)。
为了提升CNN的性能和训练稳定性,通常还会加入批归一化层和 Dropout 层。
Total words: 2531
Comments