预训练
预训练
1. 模型训练的思想
预训练的目的是确保模型能处理大规模、多样化的数据集。我们需要在架构和工程上做好准备,让模型能够“吃得下”并且“消化得了”这种级别的数据。
在预训练中,为了实现大规模的训练,我们需要放弃昂贵且有限的人工标注数据,采用自监督学习,让模型直接从海量的、无标注的原始文本中自我学习。
2. 子词模型
传统模型的词汇表
传统模型对词汇表(Vocabulary) 有如下的假设:
- 模型有一个事先定义好的词汇表,这个表通常包含几万个最常见的词,它是根据训练数据集构建的,是固定的、有限的。
- 在模型训练完成后,如果遇到任何不在这个固定词汇表里的新词,模型无法理解它。这些新词会被统一映射到一个特殊的标记——
UNK(代表 "Unknown" 未知)。
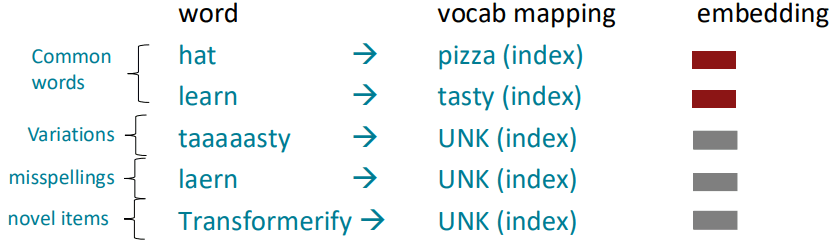
对于被归为 UNK 的词,模型给它们的词向量是完全一样的。这意味着模型完全丢失了这些词的潜在信息。"taaaaasty" 和 "laern" 在模型看来没有任何区别,它们的独有含义都消失了。这严重影响了模型处理真实世界中充满创意、错误和变化的语言的能力。
子词模型
为了解决这个弊端,我们不以整个词为最小的表示单元,而是采用一种更细粒度的表示方法:子词模型 (Subword Models)。
在子词模型中,一个完整的词不再是最小的单位,词会被拆分成更小的有意义的单元(比如 Transformerify 可以被拆成 Transform 和 er 和 ify)。这种方式可以:
- 大大减少
UNK的出现: 大多数新词都可以由已知的子词组合而成。 - 保留部分语义: 即使遇到不完全认识的词,模型也能从认识的子词部分(如 Transform)来推断它的意思,而不是完全将其视为未知。
- 共享信息: 像
learn,learning,learner这样的词可以共享子词 learn 的信息,让模型学习更高效。
字节对编码算法
构建子词词汇表的一种主流算法是字节对编码(Byte-Pair Encoding, BPE),它构建子词词汇表的策略如下:
- 从一个只包含单个字符和一个“词尾”符号的词汇表开始。
- 在一个文本语料库上,找到最常相邻出现的字符对
a,b,然后把ab作为一个新的子词添加到词汇表中。 - 将**语料库中所有出现的字符对
a,b替换成新的子词ab**,然后重复这个过程,直到达到期望的词汇表大小。
下面我们通过一个具体的例子来了解算法的具体流程:
假设我们的语料库是:
lowlowlowlowerlowest,我们期望的最终词汇表大小是12。
- 初始化:
- 给每个单词加上一个特殊的“词尾”符号,比如
</w>来区分单词的边界。语料库变为:low</w>,low</w>,low</w>,lower</w>,lowest</w> - 将所有单词拆分成最基本的字符。我们的初始词汇表就是所有出现过的单个字符加上词尾符号:
{'l', 'o', 'w', 'e', 'r', 's', 't', '</w>'}(共8个) - 此时的语料库如下:
l o w </w>(3次)l o w e r </w>(1次)l o w e s t </w>(1次)
- 给每个单词加上一个特殊的“词尾”符号,比如
- 迭代合并:
- 迭代 1:
- 寻找最高频相邻对: 在语料库中,我们统计所有相邻字符对的频率:
('l', 'o')出现了5次,('o', 'w')出现了5次。假设我们先选('l', 'o')。 - 合并: 我们将
'lo'作为一个新的子词添加到词汇表中。词汇表现在是:{..., 'lo'}(共9个)。 - 替换: 将语料库中所有的
'l', 'o'对替换成'lo'。语料库变为:lo w </w>(3次)lo w e r </w>(1次)lo w e s t </w>(1次)
- 寻找最高频相邻对: 在语料库中,我们统计所有相邻字符对的频率:
- 迭代 2:
- 寻找最高频相邻对: 现在的最高频对是
('lo', 'w'),出现了5次。 - 合并: 添加
'low'到词汇表。词汇表现在是:{..., 'lo', 'low'}(共10个)。 - 替换: 语料库变为:
low </w>(3次)low e r </w>(1次)low e s t </w>(1次)
- 寻找最高频相邻对: 现在的最高频对是
- 迭代 3:
- 寻找最高频相邻对: 现在的最高频对是
('low', '</w>'),出现了3次。 - 合并: 添加
'low</w>'到词汇表。词汇表现在是:{..., 'low</w>'}(共11个)。 - 替换: 语料库变为:
low</w>(3次)low e r </w>(1次)low e s t </w>(1次)
- 寻找最高频相邻对: 现在的最高频对是
- 迭代 4:
- 寻找最高频相邻对: 剩下的相邻对频率都是1,如
('e', 's')和('s', 't')。我们选('es')。 - 合并: 添加
'es'到词汇表。词汇表现在是:{..., 'es'}(共12个)。 - 达到目标! 我们的词汇表大小达到了12,算法停止。
- 寻找最高频相邻对: 剩下的相邻对频率都是1,如
- 迭代 1:
最终,我们的子词词汇表构建完成。当再遇到新词 lowest 时,它可以被切分成 ['low', 'est'](假设 est 也在后续的合并中生成了),而不是被当作一个 UNK。
3. 预训练
预训练流程
在 2017 年之前,预训练的总体流程如下:
- 使用预训练词向量。
- 为特定任务从零开始训练一个“上下文模型”。
这个新模型的输入层会加载第一阶段预训练好的词向量。这个模型几乎所有其他部分的参数都是随机初始化的,我们需要利用预训练好的词向量层从零开始教会模型如何理解和运用上下文信息。
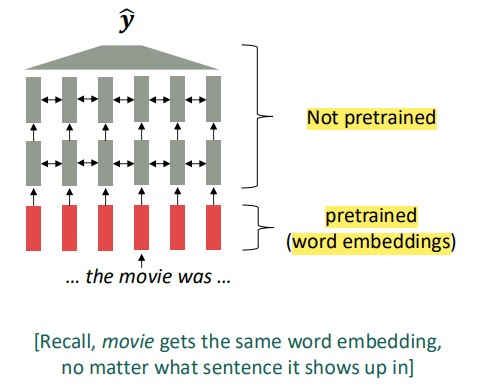
这一架构有下面这些问题:
- 模型主体对语言的上下文理解能力是从零(随机参数)开始的,它学习理解语法、语义、逻辑、常识的唯一途径,就是我们为这个特定任务准备的预训练词向量。这对下游任务的数据量要求过高。
- 一个典型的NLP模型中,词向量层的参数量只占很小一部分。真正负责复杂逻辑和上下文理解的模型主体包含了绝大多数的参数。而绝大部分参数的随机初始化导致我们每次解决一个新任务时,都需要重新搭建模型的所有参数,这十分低效。
而现在的 NLP 采用整体预训练的方法:一个网络中所有(或几乎所有)的参数都是通过预训练来初始化的:
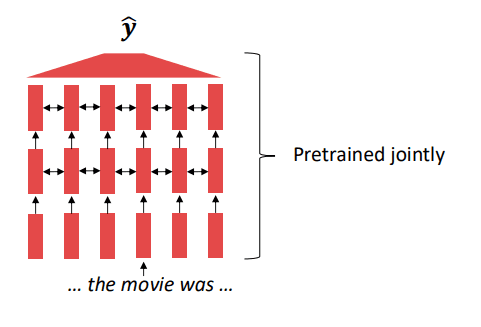
词的表示能力和理解上下文的能力是在预训练阶段同时、联合学到的。一个词的最终表示(向量)是整个模型根据其上下文动态计算出来的,而不是从一个固定的表格里查询出来的。
这些被保存下来的参数,就不再是随机初始化的了。它们内部已经编码了大量的语言知识,包括语法、词义、事实、甚至一些常识推理能力。这套保存下来的参数,就是我们所说的“预训练模型”。
通过语言建模进行预训练
语言建模任务
语言建模任务,即根据前面出现过的所有词,预测下一个词是什么的概率:
我们通过让模型进行语言建模任务来预训练模型。
语言建模任务主要有以下两种:
- 完形填空:从一句话里随机遮盖(mask)掉一些词,然后让模型去预测被遮盖掉的词应该是什么。
- 例如: 给模型输入 我今天去了[MASK]买东西,然后去看了场[MASK],模型需要学习预测出第一个 [MASK] 是“商店”或“超市”,第二个 [MASK] 是“电影”。
- 为了能准确地填词,模型必须深刻理解句子中其他词的含义以及它们之间的语法和逻辑关系,这就强迫模型去学习上下文。
- 文字接龙:给模型一句话的开头,让它去预测下一个最可能的词是什么。
- 例如:给模型输入 今天天气真不错,我们一起去,模型需要学习预测出下一个词可能是“公园”、“散步”等。
- 同样,为了能准确地“接龙”,模型必须理解前面所有文字构成的上下文。
预训练-微调范式
在完成对模型的预训练后,我们还需要针对具体下游任务进行训练:
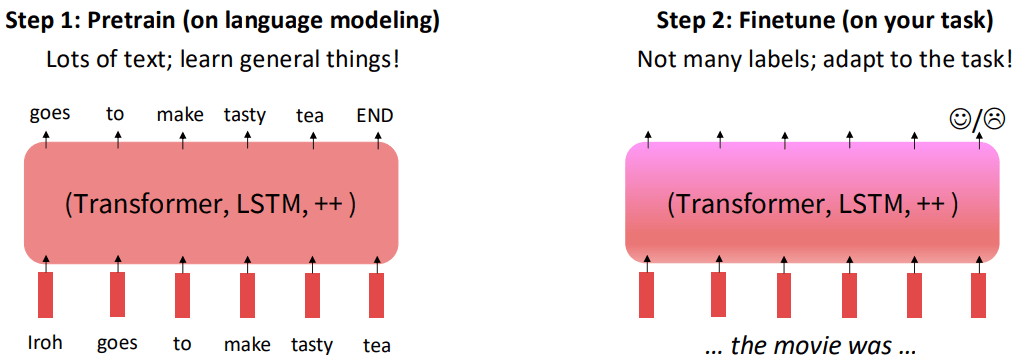
这一过程不需要很多带标签的数据,可能只需要几千甚至几百个标注好的例子。大致流程如下:
- 加载保存的预训练模型的所有参数。
- 根据新任务调整模型结构。通常只需换掉模型最顶部的输出层。例如,原来输出层是预测词汇表中的下一个词,现在换成一个只有两个输出(正面/负面)的分类层。
- 用少量带标签的任务数据继续训练整个模型。因为模型已经有了强大的语言基础,它能很快地学会如何将这些基础知识应用到新任务上。
4. 预训练架构
编码器预训练架构
编码器是双向的,能看到全局信息。于是我们可以用**掩码语言建模 (Masked Language Model, MLM)**的方法给它设定预训练目标:
- 从输入句子中,随机选择一部分词。
- 用一个特殊的
[MASK]标记替换掉这些被选中的词。 - 将这个被“破坏”过的句子输入到编码器中。
- 编码器的任务是,根据被遮盖位置的左右双向上下文,准确地预测出这些位置上原本的词是什么。
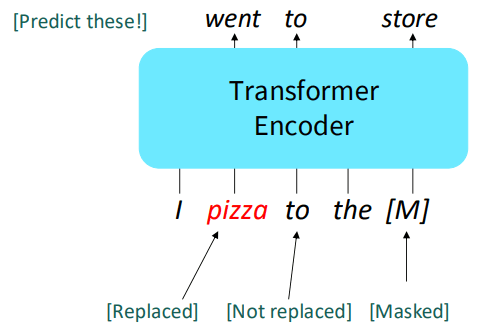
Bert(Bidirectional Encoder Representations from Transformers)模型采用了一个非常精妙的80/10/10的MLM策略:
- 80% 的情况下,用
[MASK]标记替换。I went to the store -> I [MASK] to the store- 这是最直接的方式,告诉模型:“这里有个词被挖掉了,请根据上下文把它填回来。”
- 10% 的情况下,用一个随机的词替换。
I went to the store -> I pizza to the store- 这是为了提升模型的辨别能力。模型不仅要理解上下文,还要能判断出在当前上下文中,某个词的出现是否合理。这强迫模型去学习每个词更精细的表示,而不仅仅是依赖
[MASK]这个特殊标记。
- 10% 的情况下,保持原词不变。
I went to the store -> I went to the store(但模型依然需要预测出这个位置是went)- 这是最微妙也最关键的一步。它解决了预训练和微调阶段的“不匹配”问题。在微调阶段,输入数据里是没有
[MASK]标记的。如果模型在预训练时,只习惯于处理带[MASK]的句子,那么它可能没有学会为正常的、未被遮盖的词生成足够好的表示。这一策略强迫模型对句子中的每一个词(无论是否被显式遮盖)都保持警惕,从而为所有词都学到强大的上下文表示。
编码器——解码器预训练架构
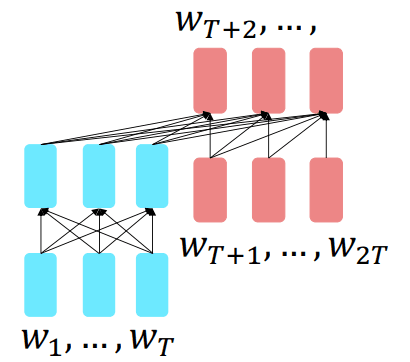
前缀语言建模
一种符合直觉的、理论上可行的预训练编码器——解码器预训练的方法是:把输入文本分成给编码器处理的部分和解码器处理的部分:
- 编码器负责“理解”前半段: 将句子的前缀部分输入给编码器。因为编码器是双向的,它可以充分、无限制地阅读整个前缀,来构建一个对这段初始上下文的深刻理解。
- 解码器负责“生成”后半段: 解码器的任务是,在充分理解了编码器传来的“前缀信息”之后,以自回归(从左到右)的方式,一个词一个词地生成句子的后半段。
- 训练目标: 模型的训练目标就是让解码器生成的后半段,与真实的后半段文本完全一致。虽然损失是在解码器的输出上计算的,但梯度会反向传播至整个模型,从而同时训练编码器和解码器。
跨度破坏(去噪)
T5 (Text-to-Text Transfer Transformer) 模型采用了跨度破坏这个更为成功预训练任务。这个预训练任务不再是简单地将句子从中间切开,而是模拟一个更普适的“修复破损文本”的场景:
- 从原始输入文本中,随机地选择一些连续的文本片段(spans)。这些片段的长度是随机的。
- 用一些唯一的、特殊的占位符(如
<X>,<Y>,<Z>...)替换掉这些被选中的文本片段。经过这一步,我们就得到了“损坏的文本”,它将作为编码器的输入。 - 我们定义一个目标文本,它由占位符和其对应的原始文本内容组成,这将是解码器的期望输出。
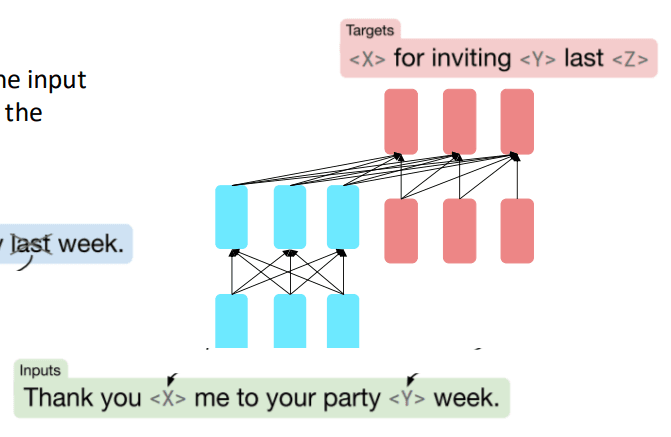
这个任务比简单地预测后半段要更难,因为它要求模型能处理多个、散落在各处、且长度不一的“破洞”。同时这种“输入损坏文本,输出修复文本”的格式,与很多下游任务(如翻译、摘要、问答)的格式惊人地一致。这使得预训练和微调阶段的目标非常统一,模型可以无缝地将预训练学到的能力迁移到各种具体任务上。。
从参数中获取知识
T5 模型有一个特性:它可以被微调来回答各种各样的问题,这些知识是从它的参数中检索出来的:它不仅仅是学会了数据中的语法和语言模式,它还将海量的世界知识 “记忆”并编码到了它那数十亿、上百亿的参数(权重和偏置)之中。
这个特性意味着,T5以及之后所有的大型语言模型,已经超越了单纯的“语言处理器”。它们在某种程度上,已经成为了一个可查询的、隐式的“知识库”。
3. 解码器训练架构
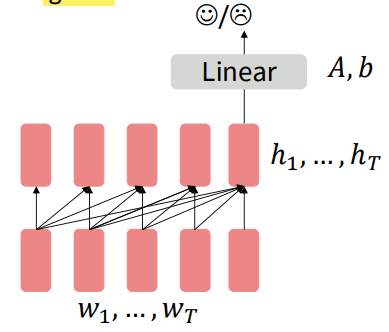
分类任务
当解码器作为“特征提取器”,用于分类任务时,我们可以忽略它作为语言模型的生成能力,而仅仅利用它强大的语言理解和表示能力:
- 将需要分类的整个文本序列 输入到预训练好的解码器中。
- 解码器从左到右处理整个序列后,我们取出最后一个词元(token)的隐藏状态 。这个 因为是在序列的末尾,它已经融合了前面所有词元的信息,可以被看作是整个输入序列的一个高质量的“总结”向量。
- 丢弃解码器原有的、用于预测下一个词的输出层。
- 在 的基础上,添加一个全新的、随机初始化的线性分类层。这个分类层的输出维度由新任务决定(如情感分类为正面/负面两个输出)。
- 用下游任务的标注数据来训练这个新模型。梯度会从这个新的分类层,一路反向传播,微调整个解码器的所有参数。
这种方法里,任务相关的“决策层” 是从零开始学习的,而解码器主体提供了一个优质的特征表示作为起点。
生成任务
这是解码器最自然、最本职的应用场景。我们可以直接利用并微调模型在预训练阶段就已经学会的生成能力 :
- 我们保留并使用整个预训练模型,包括它最后那个用于从词汇表中选择下一个词的线性输出层。
- 在新的生成任务上进行微调。如:
- 对话系统: 输入是对话历史,期望输出是下一句回复。
- 文本摘要: 输入是长篇文章,期望输出是简短的摘要。
- 模型在这些新的“上下文 -> 目标序列”数据对上进行训练,从而让它的生成风格和内容更适应特定任务的需求。
这种方法里,模型的“决策层” 也已经被预训练过了,我们只是在它的基础上进行微调,而不是从零开始。
GPT-1的微调技巧——输入格式化
GPT-1的微调解决了一个关键的工程问题:解码器天生只能处理单个连续的文本序列,那如何让它去解决需要输入两个句子的下游任务呢?(比如自然语言推理NLI,需要判断“前提”和“假设”两句话的关系)GPT-1给出的方法是:通过特殊的输入格式,将结构化输入“拍平”成一个单一序列。
- 拼接: 将“前提”和“假设”两个句子拼接在一起。
- 添加分隔符: 在两个句子之间,插入一个特殊的分隔符
[DELIM],来告诉模型这两部分是独立的。 - 添加起止/提取符: 在整个序列的开头和结尾,分别加上
[START]和[EXTRACT]这种特殊标记。
- 在微调时,不再像范式一那样使用最后一个词的隐藏状态,而是专门使用
[EXTRACT]这个特殊标记所对应的隐藏状态,来作为整个输入对的“总结”向量。 - 然后,将这个向量输入到新添加的、随机初始化的分类层中,来做出最终的判断(比如“蕴含”、“矛盾”或“中立”)。
这种巧妙的格式化技巧,使得单一的解码器架构也能够灵活地处理多种不同输入结构的任务,增强了模型的通用性。
5. 情景学习
概述
在GPT-3出现之前,我们与预训练模型交互的两种主要方式:
- 直接采样 (Sample): 给模型一个提示(prompt),然后让它像GPT-2那样自由生成后续内容。
- 微调 (Fine-tune): 在特定任务的标注数据上,更新模型的权重参数,使其“专业化”。
而 GPT-3 这种超大型语言模型似乎能够在没有梯度更新的情况下,仅仅通过上下文中提供的例子,就进行某种形式的学习。
例如,用户在单次输入(一个prompt)中,为模型提供了几个范例:
thanks -> mercihello -> bonjourmint -> menthe
然后,用户给出真正想查询的词,并留出空白让模型作答:
otter -> ?
模型看到这个上下文后,立刻“理解”了用户想要它做什么,并准确地生成了答案 loutre。
这一流程的特征如下:
- 没有微调: 在这个过程中,模型的任何权重参数都没有被改变。
- “即时学习”: 模型仅仅通过分析输入的几个例子,就当场学会了“英译法”这个新技能,并立刻应用到了新的查询上。
- 这是一种模式识别和任务推断。在海量的预训练过程中,GPT-3不仅学习了语言和知识,更学会了“学习”本身。它在数据中见过了无数种
A -> B这样的类比、转换和任务模式。当给它几个例子时,相当于是在激活它脑中已经存在的、与这种任务模式相关的神经通路。
情景学习的实质
我们在提示(Prompt)中提供的那几个例子,其作用远不止是几个孤立的、供模型参考的事实。它们实际上是在用自然语言给模型“编程”或“下达指令”。例如前面的例子,可以理解为:
“接下来我要你执行‘英译法’这个任务。任务的输入格式是‘英文词’,输出格式是‘法文词’,用 -> 分隔。”
如果只输入 otter ->,模型可能会感到困惑。而前面给出的几个例子为模型消除了这种歧义,清晰地指定了它当前应该扮演的角色——一个英语到法语的翻译器。
在接收任务后,模型通过调整自身的“下一个词预测”的概率,来模仿出我们期望它完成的任务。它不是真的在执行任务,而是在做一个数学上的计算:
- 当模型接收到包含范例的整个提示后,这个长长的、结构化的提示整体成为了它计算概率的条件。
- 这个新的条件改变了模型的概率分布。因为模型在预训练时见过无数类似
A -> B的模式,它的神经网络现在被引导到了一个特殊的状态。 - 在这个状态下,当它看到
otter ->时,其内部计算会使得后续生成loutre这个词序列的概率被提到最高,而生成其他任何词的概率则被急剧压低。
这种“模拟”并非完美无缺。它只是在概率上使得正确的输出可能性最大,但并不保证100%正确。如果任务过于复杂,或者范例给得不好,这种“模拟”可能就会失败,导致模型输出错误或无意义的内容。
最合理的解释是,情境学习是两种能力的结合:
- 推断任务 (Infer the task): 模型从范例中快速识别出任务的表面形式和结构。
- 学习任务 (Learn the task): 模型的参数中,确实已经通过预训练真正学到了关于世界的大量知识和深层联系。
- 当模型看到
thanks -> merci时,它既识别出了A -> B的格式(推断任务),也激活了其内部关于“英语”和“法语”的知识(学习任务),两者结合,才产生了正确的结果。
Comments